Cet exercice vous conduit à travers le processus de visualisation de données dans R. Il présuppose que vous connaissez déjà les bases de maniement de R et de RStudio.
Charger les données
Téléchargement
Téléchargez le fichier unine_exercice1.zip depuis le site du cours.
Décompressez le contenu de l’archive zip dans un dossier de votre choix, par exemple dans c:\\unine\cours\data sur un ordinateur Windows ou /Users/votre_nom_d_utilisateur/unine/cours/data sur un Mac. Après l’opération, un nouveau sous-dossier devrait exister dans ce dossier, par exemple:
c:\\unine\cours\data\unine_exercice1ou/Users/votre_nom_d_utilisateur/unine/cours/data/unine_exercice1.
Ouvrez le dossier en question pour vérifier qu’il contient bien des données.
Importer les données dans R
Créez un nouveau script R et enregistrez-le. Vous ajouterez progressivement les commandes ci-dessous à ce fichier, de manière à pouvoir exécuter le script dans le futur.
Définir un dossier de travail (working directory)
Le dossier de travail (working dirctory) est le lieu où R va non seulement chercher les données mais aussi déposer tous les fichiers (images, tableaux etc.) produits par vos scripts, à moins que vous n’indiquiez explicitement, dans ces scripts, de faire autrement. Cela sera pratique plus tard pour retrouver vos données plus tard.
Pour faciliter l’accès aux données que vous venez de télécharger, changez le “working directory” avec la commande setwd(). Si vous avez nommé vos dossiers comme dans l’exemple précédent, cela donnera, sur Windows (notez qu’il faut utiliser / au lieu de \ dans l’adresse):
setwd("c:/unine/cours/data")Code language: JavaScript (javascript)ou, sur un Mac:
setwd("/Users/votre_nom_d_utilisateur/unine/cours/data")Code language: JavaScript (javascript)Si aucune des deux commandes ci-dessus ne marche, vérifiez que vous n’avez pas fait des erreurs dans l’adresse et réessayez. Si vous n’y arrivez pas malgré tout, continuez avec le commandes suivantes de cet exercice. Choisir un working directory est très pratique mais pas essentiel pour la suite de cet exercice.
Définir l’adresse des données
Pour charger les données, définissez d’abord l’adresse où elles se trouvent dans votre working directory. En l’occurrence dans le fichier donnees_communes.xls, lui même situé dans les sous-dossier unine_exercice1. La commande file.path() permet d’indiquer cette adresse de manière indépendante du système d’exploitation. L’utiliser peut être pratique si vous travaillez sur une machine Windows et continuez sur une machine Linux ou Mac.
adresse_fichier <- file.path("unine_exercice1","donnees_communes.xls")Code language: JavaScript (javascript)Si, dans la section précédente, vous n’avez pas réussi à définir le working directory, vous pouvez aussi charger le fichier directement avec la commande suivante:
adresse_fichier <- file.choose()Code language: CSS (css)Pour voir si l’adresse a été bien enregistrée, exécutez adresse_fichier (c’est-à-dire écrivez ce nom de variable dans une nouvelle ligne, sélectionnez-la et pressez Ctr-ENTER ou Command-Enter). Une chaîne de caractères devrait s’afficher dans la console. Si vous êtes sur une machine Windows, comparez cette chaîne de caractères à celle obtenue par votre voisin_e sur une machine Mac ou vice versa. Quelle différence voyez-vous?
Charger les données et les stocker dans une variable R
Les données étant stockées dans un fichier Excel, vous aurez besoin du module readxl pour les charger. Assurez-vous qu’il soit installé et activez le:
if (!require("readxl")) {install.packages('readxl');require("readxl")}Code language: R (r)Chargez enfin les données et stockez-les dans une variable avec la commande suivante:
rfpdata <- read_excel(adresse_fichier, na="", sheet="GEOSTAT_ORT01_vz2000_nzpers")Code language: R (r)Examinez vos données en sélectionnant des sous-ensembles (subsetting)
Vous venez de stocker un tableau de données dans la variable rfpdata. R permet d’accéder aux colonnes du tableau à l’aide du signe $. Essayez:
rfpdata$P00B21Code language: PHP (php)Essayez de lister les valeurs d’autres colonnes.
R permet également d’afficher un sous-ensemble de données. Avec la commande suivant, affichez la 1ère colonne et les colonnes 5 à 10 :
rfpdata[c(1,5:10)]Code language: CSS (css)Affichez toutes les colonnes, sauf les colonnes 7 à 10 :
rfpdata[-c(7:10)]Code language: CSS (css)Affichez les 2 premières lignes :
rfpdata[1:2,]Code language: CSS (css)Affichez les 2 premières colonnes:
rfpdata[,1:2]Code language: CSS (css)Affichez les valeurs de la variable P00BTOT pour les 2 premières lignes:
rfpdata[1:2,]$P00BTOTCode language: PHP (php)Listez toutes les données des communes dont la population est inférieure à 2000 personnes:
rfpdata[rfpdata$P00BTOT<2000,]Code language: CSS (css)Listez les noms des communes dont la population est inférieure à 2000
rfpdata[rfpdata$P00BTOT<2000,]$GMDENAMECode language: PHP (php)Vous pouvez aussi stocker le sous-ensemble de données dans une variable
petites_communes <- rfpdata[rfpdata$P00BTOT<2000,]$GMDENAMECode language: PHP (php)Apprenez davantage sur la sélection de sous-ensembles dans R sur cette page internet. Testez les différentes options sur vos données.
Sélectionnez les données et calculez les données proportionnelles
Créez de nouvelles colonnes en calculant de nouvelles variables (vecteurs) qui seront ajoutées comme colonnes au tableau de données (data.frame) rfpdata:
rfpdata$p_P00B21 <- rfpdata$P00B21 / rfpdata$P00BTOT # la proportion des francophones
rfpdata$p_P00B22 <- rfpdata$P00B22 / rfpdata$P00BTOT # la proportion des germanophones
rfpdata$p_P00B23 <- rfpdata$P00B23 / rfpdata$P00BTOT # la proportion des germanophones
rfpdata$p_P00B24 <- rfpdata$P00B24 / rfpdata$P00BTOT # la proportion des locuteurs du romanche
rfpdata$p_P00B25 <- rfpdata$P00B25 / rfpdata$P00BTOT # la proportion des anglophonesCode language: PHP (php)Créez une nouvelle data.frame nommée langues, ne contenant que les variables qui nous intéresseront pour la suite de l’exercice.
langues <- data.frame(rfpdata$p_P00B21, rfpdata$p_P00B22, rfpdata$p_P00B23, rfpdata$p_P00B24, rfpdata$p_P00B25, rfpdata$P00BTOT)
colnames(langues) <- c("germanophones", "francophones", "italophones", "romanchophones", "anglophones", "population_totale")
rownames(langues) <- rfpdata$GMDENAMECode language: PHP (php)Stripchart
1 dimension
Le stripchart, aussi appelé scatterplot à 1 dimension, permet de visualiser la répartition des données sur une dimension (c’est-à-dire une variable) à la fois.
stripchart(langues$germanophones,xlab="Proportion de germanophones")Code language: PHP (php)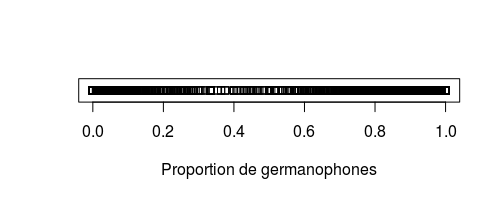
Plusieurs distributions unidimensionnelles
Plusieurs stripcharts alignés permettent de comparer la distribution unidimensionnelle de plusieurs variables
stripchart(langues,vertical=TRUE)Code language: R (r)
Comme vous le constatez, ce résultat visuel est décevant. On voit bien la répartition de la population totale mais pas celle des proportions de langues parlées. C’est normal: ces proportions varient entre 0 et 1, tandis que la population varie entre 1 et 8440. Vérifiez-le par vous-mêmes:
min(langues$population_totale)
max(langues$population_totale)Code language: R (r)Pour une visualisation plus parlante, il faut faire en sorte que toutes les valeurs soient comprises entre 0 et 1. Pour cela, il suffit de les mettre à l’échelle en divisant chaque valeur par le maximum de sa colonne. Ce maximum est forcément 1 pour les valeurs proportionnelles (germanophones, franncophones, etc.). Il est équivalent à la population maximale pour la population des communes:
scaler <- c(1,1,1,1,1,max(langues$population_totale))
langues.scaled <- data.frame(t(t(langues)/scaler))
stripchart(langues.scaled,vertical=TRUE)Code language: R (r)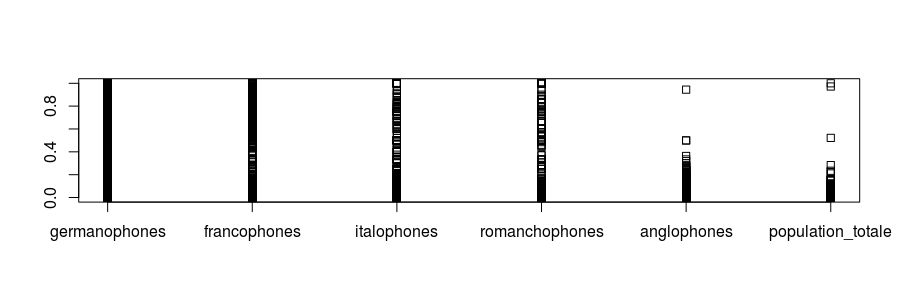
Scatterplots
Passons à deux dimensions et plus.
2 dimensions
Pour ce graphique et les suivants vous aurez besoin du module ggplot2, standard établi dans les graphismes avec R. Assurez-vous qu’il soit installé et jetez un coup d’oeil à sa documentation. Un cours entier pourrait être consacré à ce module seul, mais sa documentation de qualité permet de progresser de manière autonome après avoir vu quelques exemples initiaux que nous allons voir ici.
Activez ggplot avec la commande library("ggplot2"). Ensuite, créez un premier graphique
g1 <- ggplot(langues, aes(x=germanophones, y=francophones)) +
geom_point() +
xlab("germanophones") +
ylab("francophones") +
ggtitle("Proportion de locuteurs dans les communes suisses")
# affichez le premier graphique:
g1Code language: R (r)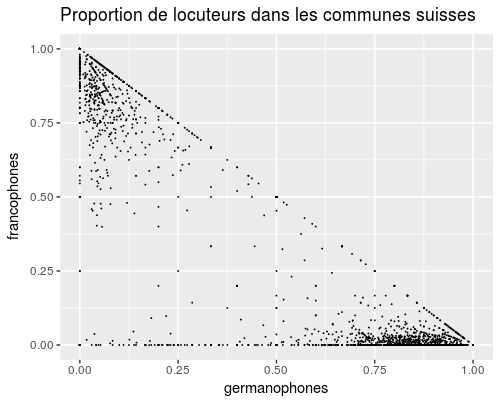
3 dimensions
La 3e dimension sera la taille. Notez l’usage du paramètre alpha sur la seconde ligne. Ce dernier dote les cercles proportionnels de transparence et permet de voir les petites communes sinon cachées par les grandes.
g2 <- ggplot(langues, aes(x=germanophones, y=francophones)) +
geom_point(aes(size=langues$population_totale),alpha=0.5) +
scale_size_continuous(range = c(0.01,10),name="population") +
xlab("germanophones") +
ylab("francophones") +
ggtitle("Proportion de locuteurs dans les communes suisses")
g2Code language: R (r)
4 dimensions
La 4e dimension sera la couleur.
g3 <- ggplot(langues, aes(x=germanophones, y=francophones)) +
geom_point(aes(size=population_totale,color=italophones),alpha=0.5) +
scale_size_continuous(range = c(0.01,10),name="population") +
scale_colour_gradient2(name="italophones",midpoint=0.25,low = "yellow", mid="orange", high = "red") +
xlab("germanophones") +
ylab("francophones") +
ggtitle("Proportion de locuteurs dans les communes suisses")
g3Code language: R (r)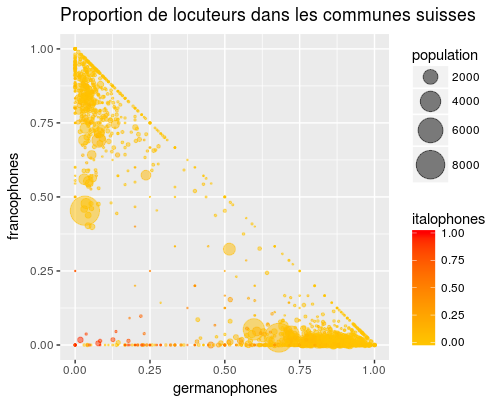
Aligner plusieurs graphiques sur une seule image
Les modules grid et gridExtra vous permettent combiner plusieurs graphiques dans une seule image en alignant les axes et les légendes. L’usage de ces modules sera plutôt rare au début, mais il est bon de les connaître. Installez-lez et exécutez les lignes suivantes.
library("grid")
library("gridExtra")
g1g <- ggplotGrob(g1)
g2g <- ggplotGrob(g2)
g3g <- ggplotGrob(g3)
g1g$widths <- g2g$widths <- g3g$widths
grid.newpage()
grid.arrange(g1g, g2g, g3g, nrow = 3)Code language: R (r)
Scatterplot 3D et bubblechart 3D
Explorez la troisième dimension de l’espace en vous assurant chaque fois que les modules requis soient installés.
3 dimensions spatiales
library("scatterplot3d")
scatterplot3d(rfpdata$p_P00B21,rfpdata$p_P00B22,rfpdata$p_P00B23,xlab="germanophones",ylab="francophones",zlab="italophones",type="h",color="red",highlight.3d=T)Code language: R (r)
4 dimensions (3 spatiales + couleur)
library("plot3D")
scatter3D(rfpdata$p_P00B21,rfpdata$p_P00B22,rfpdata$p_P00B23) # based on plot3D
scatter3D(rfpdata$p_P00B21,rfpdata$p_P00B22,rfpdata$p_P00B23, phi=40, theta=90) # ici, on fixe l'angle de vueCode language: R (r)
3D spatiale interactive avec le module rgl
Pour visualiser les objets 3d dans une fenêtre interactive, R a besoin du module “rgl” qui se sert lui-même d’une application externe nommée XQuartz. Lorsque vous installez rgl (à l’aide du gestionnaire de modules de RStudio ou avec la commande install.packages("rgl")) R vous demande d’installer XQuartz. Cela ne devrait pas demander une intervention particulière de votre part, l’installation se faisant automatiquement. Cependant, si cette installation vous pose problème, passez à la variante threejs plus bas, ou laissez tomber la 3d et procédez à la partie “Parallel coordinates” du présent tutoriel.
library("rgl")
plot3d(x=rfpdata$p_P00B21,y=rfpdata$p_P00B22,z=rfpdata$p_P00B23) Code language: R (r)
5 dimensions et plus
# Construire une palette de couleurs
rbPal <- colorRampPalette(c('red','blue')
langues.colors <- rbPal(10)[as.numeric(cut(langues.scaled$romanchophones,breaks = 10))]
library("rgl") # nécessaire seulement si le module n'est pas encore chargé
spheres3d(langues.scaled$germanophones,langues.scaled$francophones,langues.scaled$italophones,radius=langues.scaled$population_totale^(1/3)/15,color=langues.colors)
axes3d()
title3d(xlab="germanophones",ylab="francophones",zlab="italophones")
Code language: R (r)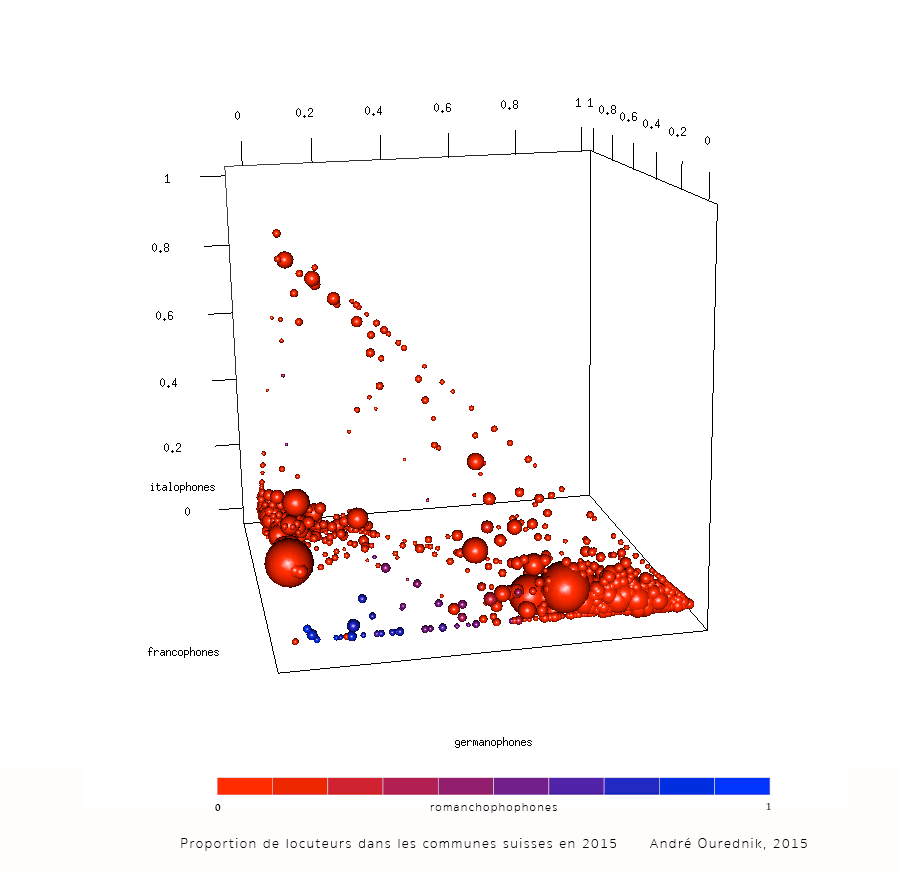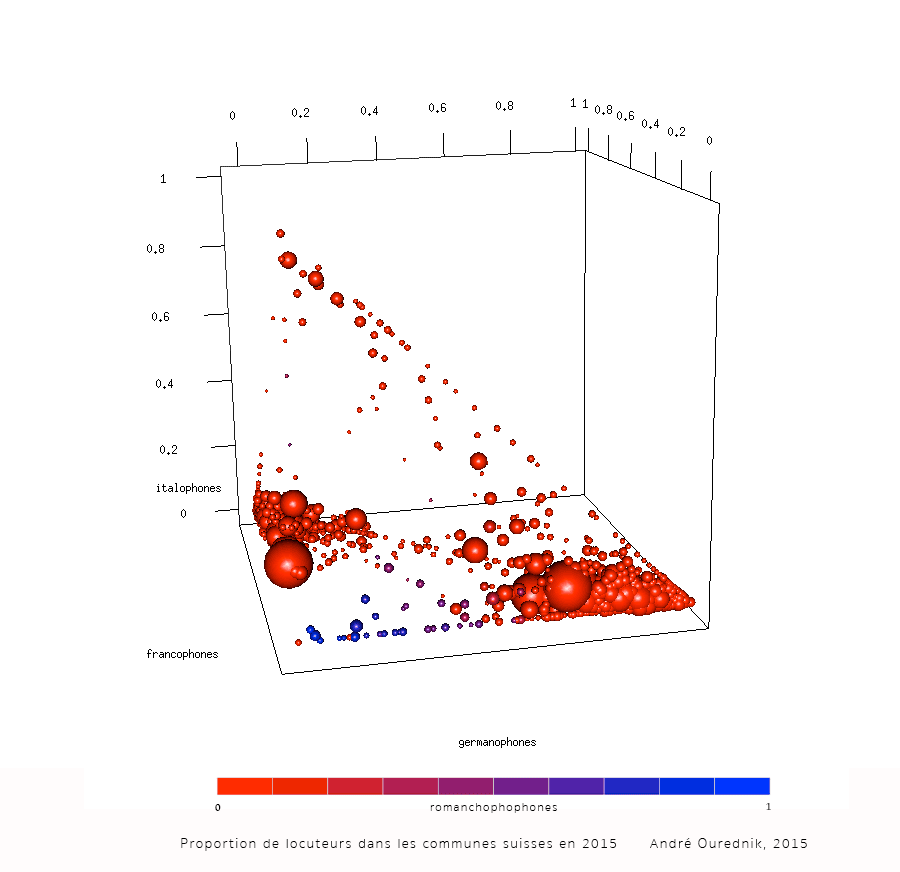
3D spatiale interactive avec le module rthreejs
Si vous ne souhaitez pas installer XQuartz, il existe désormais une alternative qui utilise la bibliothèque javascript threejs. Cette dernière permet d’afficher des objets 3D dans une fenêtre de navigateur web (Firefox, Chrome etc.) en faisant appel à WebGL (un moteur de rendu 3d incorporé dans tous le navigateurs récents). Remarquez la similarité des paramètres de la fonction scatterplot3js() avec ceux de scatterplot3d().
library(threejs)
scatterplot3js(x=rfpdata$p_P00B21,y=rfpdata$p_P00B22,z=rfpdata$p_P00B23,size = 0.2)Code language: PHP (php)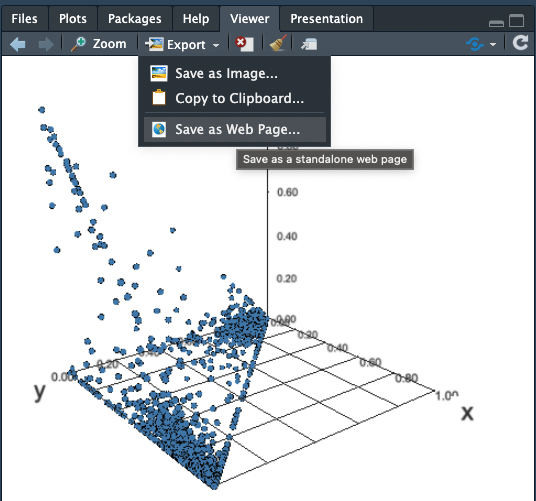
L’avantage de cette approche est que vous pouvez exporter le graphique en tant que page web et l’afficher sur un site. Essayez:
Le désavantage de cette approche est que le module threejs pour R est, pour l’heure, très limité dans ses options graphiques.
Parallel coordinates
Pour visualiser les coordonnées parallèles, assurez-vous d’avoir installé le module MASS.
library("MASS")
parcoord(langues, col = rainbow(length(langues[,1])), lty = 1, var.label = TRUE)Code language: R (r)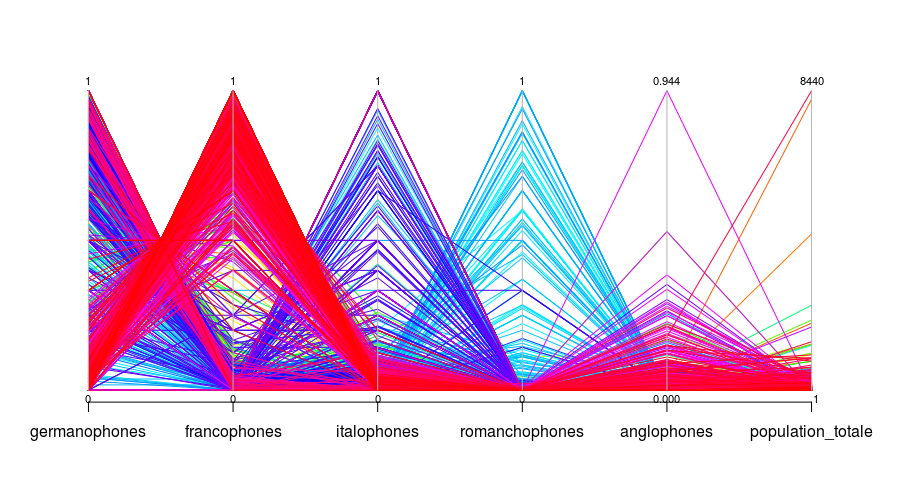
Pour montrer le profil du pays entier:
colMax <- function (colData) { apply(colData, MARGIN=c(2), max) }
colMin <- function (colData) { apply(colData, MARGIN=c(2), min) }
langues.means <- data.frame(rbind(t(colMax(langues)),t(colMin(langues)),t(colMeans(langues))))
parcoord(langues.means, col = 1, lty = 1, var.label = TRUE)Code language: R (r)Il sera cependant plus beau, car plus compact, de montrer les données moyennes retenues dans le data.frame langues.means sous forme de radar chart.
Radar charts et wind-rose chart
Les radar charts peuvent être construits à l’aide de la bibliothèque fmsb de Minato Nakazawa. Ce type de graphique ne peut-être produit que si on donne les maxima et les minima pour chaque colonne de la data.frame servant de source de données. Un article spécial de ce blog est dédié aux détails pour la production des radar charts à partir de n’importe quel ensemble de données.
library("fmsb")
radarchart(langues.means)Code language: JavaScript (javascript)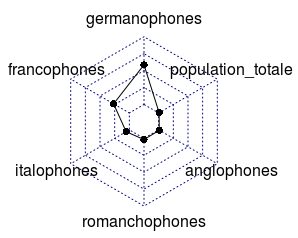
radarchart(data.frame(rbind(t(colMax(langues)),t(colMin(langues)),langues[1,]))) # la radarchart ne fonctionne que si on donne les maxima et les minima pour chaque colonne dans les lignes 1 et 2 du dataframe
langues.zuerich <- langues[match("Zürich",rfpdata$GMDENAME),] # match() permet de tourver la ligne correspondant à Zürich. On aurait aussi pu utiliser les rownames. Ceci est une variante.
langues.geneve <- langues[match("Genève",rfpdata$GMDENAME),]
langues.scuol <- langues[match("Scuol",rfpdata$GMDENAME),]
radarchart(data.frame(rbind(t(colMax(langues)),t(colMin(langues)),t(colMeans(langues)),langues.zuerich)),pfcol = c("grey",NA),pty = 32, plty=1, pcol=c("grey",2))Code language: R (r)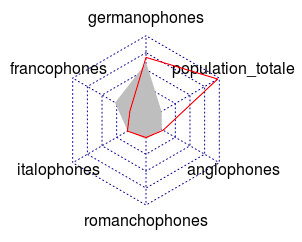
radarchart(data.frame(rbind(t(colMax(langues)),t(colMin(langues)),t(colMeans(langues)),langues.geneve)),pfcol = c("grey",NA),pty = 32, plty=1, pcol=c("grey",2))
radarchart(data.frame(rbind(t(colMax(langues)),t(colMin(langues)),t(colMeans(langues)),langues.scuol)),pfcol = c("grey",NA),pty = 32, plty=1, pcol=c("grey",2))
radarchart(data.frame(rbind(t(colMax(langues)),t(colMin(langues)),langues.zuerich,langues.geneve)),pfcol = c(NA,NA),pty = 32, plty=1, pcol=c(2,3))Code language: R (r)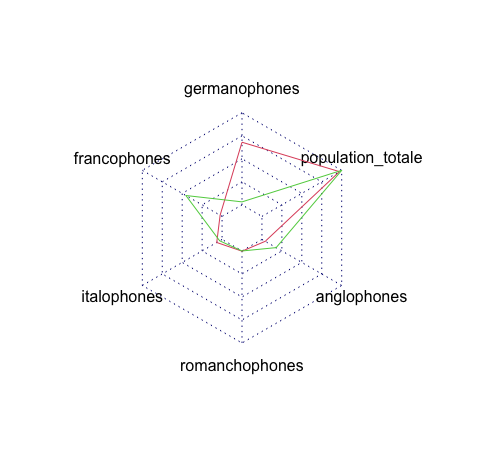
Les wind-rose charts
Les wind-rose charts sont une variante de la radar-chart.
stars(t(t(rbind(langues.zuerich,langues.geneve,langues.scuol))/scaler), labels=c("Zurich","Genève","Scuol"),radius = T,draw.segments = F,key.loc=c(5,2), mar=c(3,3,3,3),scale=F) # The key.loc refers to the axes. Try option axes=T to see these axes
stars(t(t(rbind(langues.zuerich,langues.geneve,langues.scuol))/scaler), labels=c("Zurich","Genève","Scuol"),radius = T,draw.segments = T,key.loc=c(5,2), mar=c(3,3,3,3),scale=F) # The key.loc refers to the axes. Try option axes=T to see these axes
langues.mostpopulated <- langues[order(-langues$population_totale),][1:20,]
stars(t(t(langues.mostpopulated)/scaler), labels=rownames(langues.mostpopulated),radius = T,key.loc=c(13,3),draw.segments = T, scale = F,mar=c(3,3,3,3))Code language: R (r)
Boxplots
Les boxplot sont, au fond, des stripcharts améliorés. On peut les produire avec la commande geom_boxplot() du module ggplot().
langues.forboxlot <- stack(langues.scaled) # melting the dataframe for ggplot boxplot
levels(langues.forboxlot$ind)
langues.forboxlot$ind = factor(langues.forboxlot$ind,labels=c("germanophones","francophones","italophones","romanchophones","anglophones", "pop. totale (en proportion du max. CH)")) # renaming the factors
ggplot(langues.forboxlot, aes(x=ind, y=values)) +
geom_boxplot(alpha=0.2) +
stat_summary(fun.y=mean,geom="point") +
xlab("locuteurs ") +
ylab("Proportion dans la population de la commune")Code language: R (r)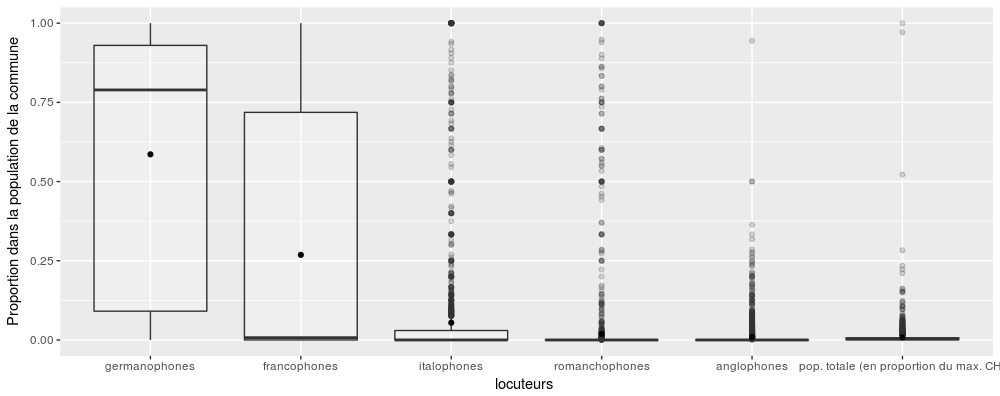
Histogramme
La fonction geom_histogram du module ggplot permet de créer de histogrammes:
histogram <- ggplot(langues, aes(x=germanophones)) +
geom_histogram(breaks=seq(0,1,by=0.05),alpha=0.5) +
xlab("proportion de germanophones") +
ylab("nombre de communes") +
scale_y_sqrt(limit=c(0,2000))
histogramCode language: R (r)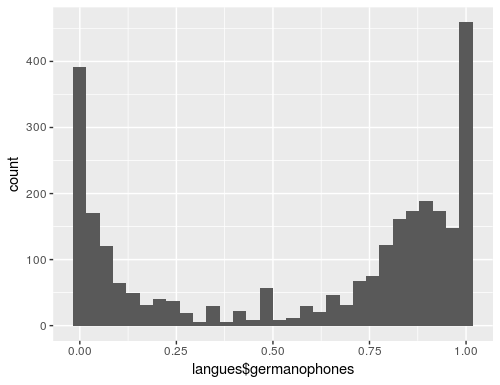
Essayez diverses largeurs des colonnes de l’histogramme.
histogram + geom_histogram(breaks=seq(0,1,by=0.2),alpha=0.5)
histogram + geom_histogram(breaks=seq(0,1,by=0.01),alpha=0.5)Code language: R (r)Superposez un kernel density plot à votre histogramme. Le kernel density plot permet de se passer de colonnes et de voir une distribution continue.
histogram <- ggplot(langues, aes(x=germanophones)) +
geom_histogram(aes(y=..density..),breaks=seq(0,1,by=0.02),alpha=0.5) +
xlab("proportion de germanophones") +
ylab("densité de probabilité")
histogram + geom_density(alpha=.2)Code language: R (r)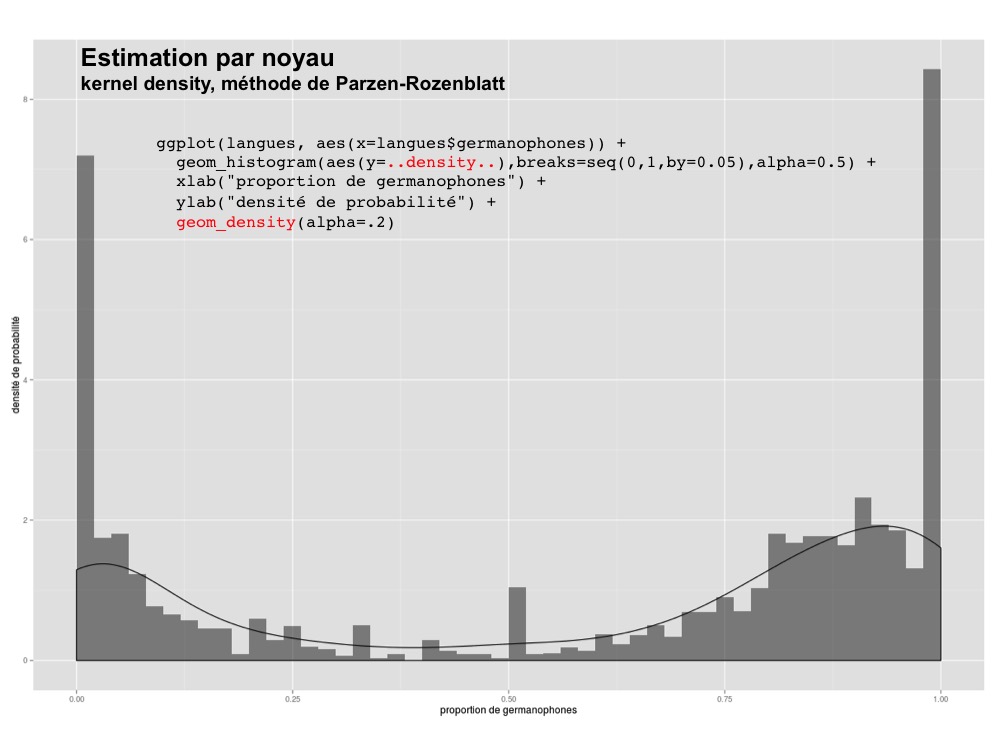
Barchart
La fonction geom_bar(stat=”identity”) a besoin du package plyr pour fonctionner. Vérifiez qu’il soit bien installé avant d’exécuter les lignes suivantes.
barchart <- ggplot(langues.mostpopulated[1:10,],aes(x=rownames(langues.mostpopulated[1:10,]),y=germanophones)) +
geom_bar(stat="identity") +
xlab("noms des communes") +
ylab("proportion de germanophones")
barchart
barchart + coord_flip()Code language: HTML, XML (xml)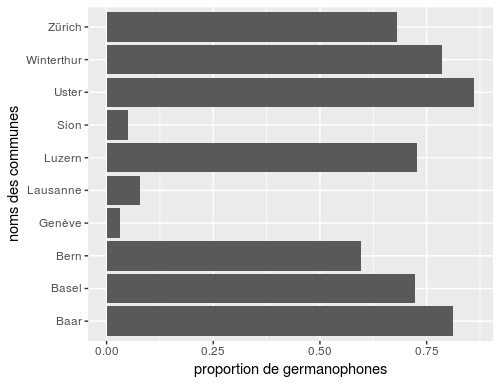
La suite…
La suite de cet exercice s’adresse aux étudiants plus avancés intéressés par les réductions dimnesionnels et le regroupement par catégorie.


