
Ce tutoriel présuppose que vous avez fait vos premiers pas avec le module R Quanteda et que vous maîtrisez les notions stemming, stopwords, matrice document-terme, etc. On part du principe que vous avez installé et activé les modules quanteda, quanteda.textstats, quanteda.textplots, readtext, seededlda et magrittr.
Créez un corpus de textes à partir de données existantes
Idéalement, vous avez déjà un ensemble de fichiers de textes groupés dans un dossier (par exemple vos transcriptions d’interviews). Demandez à R d’ingérer tout le contenu de ce dossier à l’aide de la fonction readtext.
mestextes <- readtext("chemin/vers/votre/dossier/de/textes") Code language: R (r)Si vous n’avez pas encore un tel dossier de textes, vous pouvez faire ingérer un exemple. Par exemple, une Collection de romans français du dix-huitième siècle:
mestextes <- readtext("chemin/vers/le/fichier/exemple_textes.zip") Code language: R (r)Astuce: notez que la fonction readtext est capable de lire non seulement des dossiers standard mais aussi des dossiers compressés (zip, tar, etc.).
À ce stade, vos textes sont stockés en mémoire dans un tableau brut avec deux colonnes. La colonne mestextes$doc_id contient le nom du document. La colonne mestextes$text contient le texte. Par défaut, lorsque la fonction readtext construit ce tableau, le nom doc_id est défini sur la base du nom de chaque fichier ingéré:
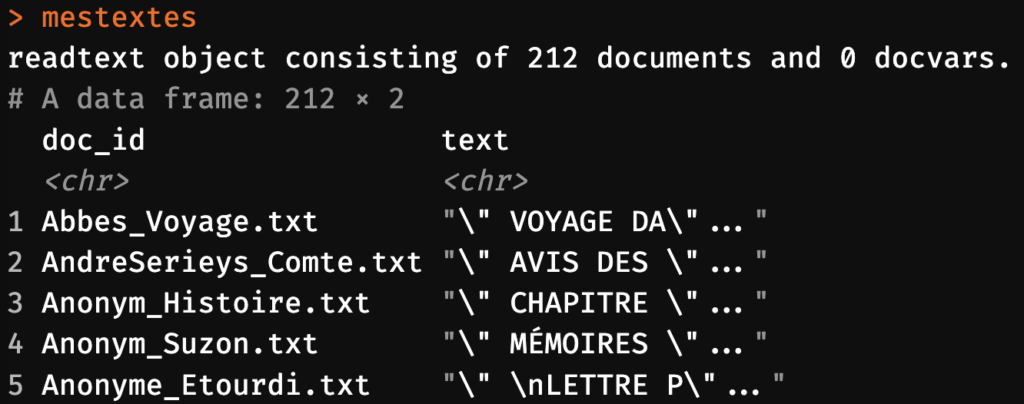
Comme vous le constatez, ces noms contiennent l’extension de fichier “.txt”. Pour éviter que cela ne dérange par la suite, notamment dans les visualisations, adaptons doc_id en enlevant l’extension à l’aide de la fonction str_replace (elle correspond à l’outil “rechercher et remplacer” d’un logiciel de traitement de texte comme Word, et permet de remplacer simplement toutes les occurrences de “.txt” par la chaîne vide “”):
mestextes$doc_id <- str_replace(mestextes$doc_id, fixed(".txt"),"")Code language: R (r)
Analysez le corpus
Pour la suite des analyses, nous transformons le tableau de type “readtext” en un objet de type Quanteda corpus de textes pour la suite des analyses:
moncorpus <- corpus(mestextes)Code language: R (r)Cette opération ne recourt à aucune analyse mais permet simplement la suite à l’aide de fonctions du module Quanteda. À commencer par la transformation du corpus de textes en un tableau de tokens. (Notez que nous utilisons du simple stemming pour éviter les redondances dans les flexions des mots [p. ex. montage – montagnes]. La lemmatisation serait plus sophistiquée, mais demande nettement plus de temps de calcul. Je la présente plus loin dans ce tutoriel.)
Comme toujours, nous enlevons les mots dépourvus de teneur sémantique pertinente pour notre analyse.
mystopwords <- c(stopwords("fr"),"si","plus","où")Code language: JavaScript (javascript)N’hésitez pas à compléter cette liste en fonction de la nature de vos données et de vos besoins. Veillez à choisir le bon langage des stopwords (ici, “fr”, mais, par exemple “en” si vous travaillez avec des textes en anglais).
Dans la chaîne de création des tokens, j’emploie aussi la commande token_split("'", valuetype = "fixed"), afin d’éviter que des mots avec déterminant à apostrophe soient traités comme distincts (“humanité”, “l’humanité”):
mestokens <- tokens(moncorpus, remove_punct=T, remove_symbols=T, remove_numbers=T) %>%
tokens_split("'", valuetype = "fixed") %>%
tokens_remove(mystopwords) %>%
tokens_wordstem(language="fr")Code language: HTML, XML (xml)Construisons à présent une matrice document-feature (DFM).
madfm <- dfm(mestokens) %>%
dfm_trim(min_termfreq = 3, max_termfreq = 300, min_docfreq=10)Code language: R (r)Regardons de plus près le code ci-dessus. Notez d’abord que nous ne conservons que des mots qui apparaissent au moins 3 fois pour réduire le bruit de notre modèle. Par contre, baissez évidemment ce paramètre min_termfreq à 1 si les mots qui n’apparaissent qu’une seule fois dans tout votre corpus sont importants pour votre analyse.
Notez aussi le paramètre max_termfreq. Ce dernier enlève au contraire les termes trop fréquents, qui peuvent dominer la matrice document-terme et obscurcir les thèmes sous-jacents. Réduire la taille de la DFM accélère en outre dramatiquement l’algorithme de détection de thématiques.
Le paramètre min_docfreq=10, enfin, signifie qu’un terme doit apparaître dans au moins 10 documents différents pour être pris en compte. Une telle contrainte n’est pas conseillée dans la majorité des analyses, mais, dans le cas de romans, elle permet d’éviter que des mots trop spécifiques à un texte unique – comme notamment les noms de ses personnages – ne dominent la définition de thèmes.
À ce stade, tout est prêt pour du topic modeling, notamment à l’aide de la méthode dite de “L’allocation de Dirichelet latente” (LDA). Il s’agit d’une méthode “non supervisée”, dans la mesure où elle ne requiert pas un set d’entraînement pour lesquels des thématiques seraient déjà déterminées à la main. Sachez néanmoins qu’il existe une méthode semi-supervisée nommée “seeded LDA“, permettant d’associer des documents à un ensemble de thèmes (topics) prédéterminés. Je ne la présente pas dans ce tutoriel pour rester focalisé sur la LDA standard.
Procédons en nous rappelant qu’il demeure indispensable de modifier les paramètres min_termfreq, max_termfreq et min_docfreq dans le code de construction de la ma_dfm ci-dessus par la suite, notamment en réaction réflexive au résultat de votre modélisation thématique, et à la lumière de votre connaissance de votre propre terrain. Le topic modeling est un processus itératif et ne saurait pas être entièrement automatisé. Autrement dit, l’approche quantitative ne vous dédouane pas de l’effort de penser votre terrain d’analyse.
Avec le module seededlda
Développé par l’équipe à l’origine du module Quanteda, le module seededlda englobe le plus ancien module topicmodels. (Comme son nom l’indique, ce module permet aussi, potentiellement, de procéder à la “seeded LDA” mentionnée plus haut et que nous ne verrons pas dans ce tutoriel). Le module permet de traiter directement un corpus de textes quanteda et donne notamment accès à la fonction textmodel_ld, qui identifie les thèmes principaux et leur présence dans les textes de ce corpus. Le paramètre k précise le nombre de thématiques que vous souhaitez. Adaptez-le selon vos besoins et vos observations. Le module R nommé “seededlda” permet aussi d’y recourir, mais
Pour m’assurer que l’analyse avance bien, je spécifie verbose=TRUE; cela me permet de suivre l’avancement du modèle. Avertissement: cette fonction peut prendre du temps; profitez-en pour vous lever, vous hydrater et faire quelques exercices.
lda_model <- textmodel_lda(my_dfm, k = 6, auto_iter= T, verbose=TRUE) Code language: R (r)
Inspectez le modèle en analysant les termes dominants chacun des 6 topics.
terms(lda_model)Code language: R (r)
Comme vous le constatez, on trouve encore trop de noms propres, effectivement fréquents, et caractéristiques pour chaque roman. Comme ils ne nous disent rien sur le propos des romans, il faudra les supprimer en amont – au même titre que les stopwords.
Comme évoqué, il est impératif de répéter ce processus d’analyse avec divers paramètres de nettoyage pour obtenir un résultat parlant. Voici le code proposé jusqu’ici, adapté pour enlever les termes sans valeur pour l’analyse:
mystopwords <- c(stopwords("fr"),"si","plus","où","a","fait","alcibiad","zéphir","paul","capucin","ste","charlott","emile","zéphire","celle-là","théodor","eléonor","martin","dois-j","elles-mêm","pierrot","jasmin","à-la-fois","julien","septembr","jenny","bernard","andré","août","suzann","à-peu-pres","mai","léon","pouvez-vous","augustin","william","roland","ajouta-t-el","même-temp","bertrand","là-b","çà","continua-t-il","quel-qu","a-t-on","par-là","de-là","aurait-il","octobr","dimanch","guillaum","nicol","ci-dev","là-haut")
mestokens <- tokens(moncorpus, remove_punct = T, remove_symbols = T, remove_numbers = T) %>%
tokens_split("'", valuetype = "fixed") %>%
tokens_wordstem(language = "fr") %>%
tokens_remove(mystopwords)
madfm <- dfm(mestokens) %>% dfm_trim(min_termfreq = 10, max_termfreq = 300, min_docfreq=9)
lda_model <- textmodel_lda(madfm, k = 6, auto_iter= T, verbose=T) # Specify the number of topics (k)
terms(lda_model,12)Code language: PHP (php)Et son résultat

Des hypothèses quant à la logique thématique plus profonde qui regroupe les mots dans chacun de ces 6 thèmes commencent à s’esquisser. À ce stade, il commence à devenir intéressant d’examiner quels livres sont associés à quelles thématiques, à l’aide de la fonction topics(lda_model):
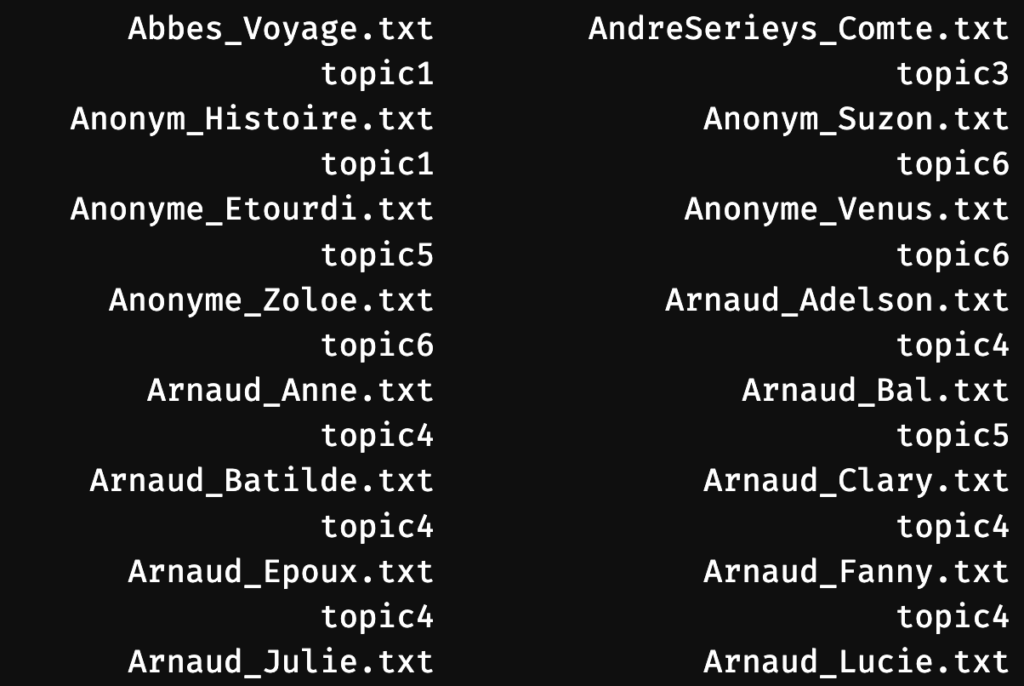
Pour avoir cette information dans un autre ordre, vous pouvez aussi exploiter le visualiseur de tableaux de RStudio:
texttopics <- data.frame(docnames(moncorpus),moncorpus$topic)
View(texttopics)Code language: PHP (php)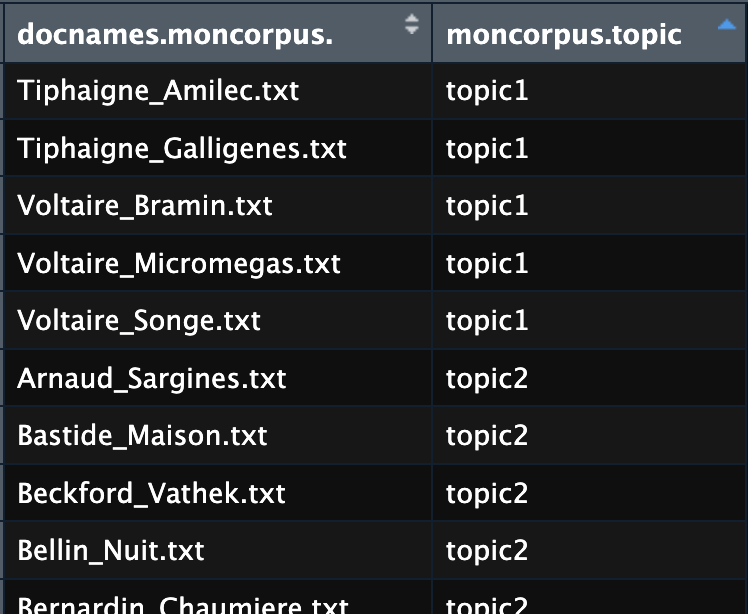
Aller plus loin
Lemmatiser plutôt que stemmer
Évidemment, le résultat sera bien meilleur si, au lieu du simple stemming, vous parvenez à lemmatiser votre corpus avant la tokenisation. Une nouvelle fois, veillez à bien spécifier la langue de votre corpus (dans mon cas, “french”) pour que le script utilise le bon modèle de lemmatisation. Je ne retiens que les noms, les verbes et les adjectifs, porteurs principaux de la signification d’un texte.
getlemma <- function(x) {
print(substr(x,1,100))
ttg <- udpipe(x,object = udmodel)
ttg <- ttg[ttg$upos %in% c("NOUN","VERB","ADJ"),]
return(paste(ttg$lemma, collapse=" "))
}
udmodel <- udpipe_download_model(language = "french")
mestexteslematises <- lapply(mestextes$text,getlemma)Code language: R (r)L’exécution de ce script sera plus longue mais son résultat vaudra la peine. Profitez du temps d’attente pour faire vos courses ou une promenade à l’extérieur.
Astuce: pour ne pas avoir à refaire la lemmatisation, je recommande de sauvegarder son résultat:
saveRDS(mestexteslematises, file = "chemin/du/dossier/de/votre/choix/mestokens.rds")Code language: R (r)Le fichier ainsi sauvegardé peut être rechargé en mémoire vive avec la commande suivante:
mestexteslemmatises <- readRDS("chemin/du/dossier/de/votre/choix/mestokens.rds")Code language: JavaScript (javascript)Il suffit dès lors de construire un véritable objet Quanteda de type “tokens” à partir de cet objet temporel en mémoire et de lui réassocier les identifiants des documents (les titres des ouvrages):
mestokens <- quanteda::tokens(unlist(mestexteslemmatises))
docnames(mestokens) <- mestextes$doc_idCode language: PHP (php)Une fois le corpus de tokens lemmatisés constitué, la suite est identique à ce que nous avons déjà vu:
madfm <- dfm(mestokens) %>%
dfm_trim(min_termfreq = 10, max_termfreq = 300, min_docfreq=9)
lda_model <- textmodel_lda(madfm, k = 6, auto_iter= T, verbose=T)
terms(lda_model,12)Code language: R (r)
Ou alors, poursuivez ce tutoriel, pour employer un autre algorithme, qui vous permettra une visualisation plus intéressante.
Plus de détails numériques et graphiques
Le module topicmodels, sur lequel est construit seededlda, mais légèrement différent, donne accès à des informations supplémentaires qui permettent aussi des graphismes plus précis. Commençons par recalculer les thèmes:
install.packages("topicmodels")
library(ggplot2)
library(stringr)
lda_model2 <- topicmodels::LDA(convert(madfm, to = "topicmodels"), k = 6)Code language: R (r)À ce stade, nous pouvons de nouveau identifier les mots principaux de chaque thème à l’aide de la fonction topicmodels::terms(lda_model2, 15):

Mais l’apport de l’usage direct du module topicmodels est surtout l’accès à la fonction topicmodels::posterior(lda_model2)$topics. Son résultat permet de ne pas associer un seul thème à chaque document, mais d’étudier la présence relative de chacun des thèmes identifiés dans chaque document. Cela vos permet de produire un graphique plus précis.
doc_topics <- topicmodels::posterior(lda_model2)$topics
df <- data.frame(doc_id = row.names(doc_topics) %>% str_replace(fixed(".txt"),""), doc_topics)
df_long <- tidyr::pivot_longer(df, cols = starts_with("X"), names_to = "topic", values_to = "importance")
p <- ggplot(df_long, aes(x = importance, y = doc_id, fill = factor(topic))) +
geom_bar(stat = "identity") +
labs(x = "Topic Importance", y = "Document ID", fill = "Topic") +
theme_minimal() +
theme(axis.text.y = element_text(angle = 0, hjust = 1))
p
ggsave("mytextsplot.png", plot= p, width=5,height=25)Code language: R (r)
Analyse du résultat avec l’intelligence artificielle
Pour peu de ne pas se reposer uniquement sur l’IA, vous pouvez tenter de soumettre vos résultats à ChatGPT, qui permet actuellement l’importation de fichiers de données.
ATTENTION ! Ne faites en aucun cas cela si vos données d’origine contiennent des données confidentielles!
Exportez les données de vos résultats:
data.table::fwrite(doc_topics %>% as.data.frame,file.path(basepath,"TopicModelling_doc_topics.csv"))
data.table::fwrite(topicmodels::terms(lda_model2, 200) %>% as.data.frame,file.path(basepath,"TopicModelling_topics.csv"))Code language: CSS (css)Vous pouvez désormais glisser les fichiers TopicModelling_doc_topics.csv et TopicModelling_topics.csv dans l’interface de dialogue de ChatGPT et demander “J’aimerais une interprétation de chacun des six topics”. Le résultat est à prendre avec précaution, et mis en lumière de votre propre expérience du terrain d’étude. Néanmoins, étant donné que les large language models, à la base des IA textuelles génératives, sont très proches de procédés statistiques comme l’allocation de Diriechelet latente (LDA), le recours à eux dans ce contexte fait particulièrement sens.
ChatGPT, version GPT-4o, 1.6.2024
- Topic 1 :
- Ce topic semble associer des termes liés à des titres ou rôles sociaux (prieur, sultan, régiment).
- Semble lié à des contextes historiques ou militaires.
- Topic 2 :
- Les mots indiquent des concepts fondamentaux ou élémentaires (germe, substance, centre, élément, industrie).
- Semble lié à la science ou à des discussions sur la nature des choses.
- Topic 3 :
- Mots variés mais avec une connotation potentiellement négative ou corporelle (décharger, cuisse, cave, pendre, téton).
- Semble lié à des descriptions physiques ou à des récits plus sombres.
- Topic 4 :
- Termes associés à des lieux et statuts (indigent, chapelle, vallée, maîtresse).
- Semble traiter de la pauvreté, de la religion, ou de relations sociales.
- Topic 5 :
- Mots évoquant des personnages historiques ou actions (écuyer, lance, trépas, calife, retentir).
- Connotation chevaleresque ou historique.
- Topic 6 :
- Termes variés avec une touche de prestige ou de formalité (supérieure, lady, courrier, fausseté, septembre).
- Semble lié à des contextes sociaux élevés ou des intrigues.
Visualisation de proximités entre documents
Enfin il peut être intéressant de voir plus systématiquement en quoi les documents se ressemblent. Comme nous savons à quel degré chaque topic est présent dans chaque document, nous pouvons calculer les distances thématiques entre les documents:
mytopicdist <- dist(doc_topics) %>% as.dist Code language: R (r)Dendrogramme
Ces distances peuvent être visualisées par exemple à l’aide d’un dendrogramme:
labels_cex(mydendro) <- 0.45
png("mytextsplot-dendro.png", width = 500, height = 3800, res=300)
par(mar = c(0, 0, 0, 6))
mydendro %>%
color_branches(k=15) %>%
color_labels(k=15) %>% plot(
horiz=T,
ylim = c(7, nleaves(mydendro)-7)
)
dev.off()Code language: R (r)
Trouvez le dendrogramme complet plus bas dans les annexes.
Réduction dimensionnelle (UMAP)
Une autre manière de représenter la proximité entre les textes consiste à réduire les 6 thématiques identifiées par l’algoritme en 2 dimensions. La valeur asociée, pour chaque texte, à chaque thémtique, peut en effet être considérée comme la position dans un espace multidimensionnel. Réduire de 6 dimensions à deux revient à une “réduction dimensionnelle”. De nombreux algorithmes le permettent (entre autres la très connue “analyse en composantes principales”). Ici, j’utilise l’algorithme UMAP à l’aide du module R éponyme. Pour éviter que les annotations des points ne se chevauchent, j’emploie ausis le module ggrepel.
library(umap)
library(ggrepel)
# rownames(doc_topics) <- mestextes$doc_id
mytopicsumap <- umap(doc_topics)
# plot(mytopicsumap$layout[,1], mytopicsumap$layout[,2])
umap_df <- data.frame(mytopicsumap$layout, row_names = rownames(doc_topics))
p <- ggplot(umap_df, aes(x = X1, y = X2, label = row_names)) +
geom_point() +
# geom_text(check_overlap = FALSE, vjust = 1.5, size=2) +
geom_text_repel(aes(label = row_names), point.padding = 0.2, segment.color = 'grey50', size=2, max.overlaps = 20) +
theme_minimal() +
labs(title = "UMAP Projection", x = "UMAP 1", y = "UMAP 2")
p
ggsave(file.path(basepath,"mytextsplot-umap.png"), plot= p, width=10,height=10)Code language: PHP (php)
Vous trouverez d’autres méthodes de visualisation de textes dans mon tutoriel Text2Landscape.
Annexe: visualisation de tous les documents

Annexe 2: dendrogramme de proximités entre tous les documents

Cliquez sur l’image pour l’ouvrir dans une nouvelle page
Annexe 3 : autres méthodes de topic modeling et de text clustering
Le domaine de l’IA est en essor rapide et il existe des méthodes plus élaborées de topic modeling que la LDA. LDA est un modèle probabiliste qui suppose que chaque document est un mélange de sujets et que chaque sujet est un mélange de mots. Il est largement utilisé dans l’exploration de textes en raison de sa simplicité et de sa facilité d’interprétation. Cependant, LDA suppose que les mots sont indépendants les uns des autres, ce qui n’est pas toujours le cas.
Une autre approche très connue consiste à recourir à BERT: un modèle basé sur un transformateur qui représente les mots en fonction du contexte. Il s’agit d’un modèle d’apprentissage profond pré-entraîné sur un large corpus de textes et qui peut être affiné pour diverses tâches de NLP, y compris le topic modeling. BERT peut capturer les relations sémantiques et syntaxiques entre les mots, ce qui peut conduire à des représentations thématiques plus précises et plus nuancées. Cependant, BERT nécessite plus de ressources informatiques et peut être plus lent que LDA.
Il est enfin possible de recourir à des séquences de méthodes combinées. La plupart exigent, comme BERT, l’usage du langage de programmation Python et ses modules. Ces approches ne font pas partie du présent tutoriel, mais il est bon d’être au courant de leur existence:
Term frequency-inverse document frequency (TF-IDF) → PCA → k-means (séquence plus ancienne, incorporant notamment l’analyse en composantes principales [PCA], mais encore d’actualité dans certains contextes)
Encodeur de phrases universel (Universal Sentence Encoder) → Kmeans clustering
LDA-sentence → BERT embeddings → Kmeans clustering
Sentence BERT embeddings → Kmeans clustering
Word2vec → Kmeans clustering
TextRank → LDA
Top2Vec : un module Python complet pour classifier les textes en fonction de leur thématique, et s’appuyant notamment sur le
Contextual Topic Identification: autre module Python s’appuyant notamment sur le puissant modèle de embeddings BERT/RoBERTa.


