
Ce tutoriel présuppose que vous avez fait vos premiers pas avec le module R Quanteda et que vous maîtrisez les notions stemming, stopwords, matrice document-terme, etc. On part du principe que vous avez installé et activé les modules quanteda, quanteda.textstats, quanteda.textplots, readtext, seededlda et magrittr. Créez un corpus de textes à partir de données existantes […]
Tag Archives: quanteda
Text2Landscape: Visualize a Text in Multiple Spaces with R — Force-directed networks, Biofabric, Word Embeddings, Principal Component Analysis and Self-Organizing Maps
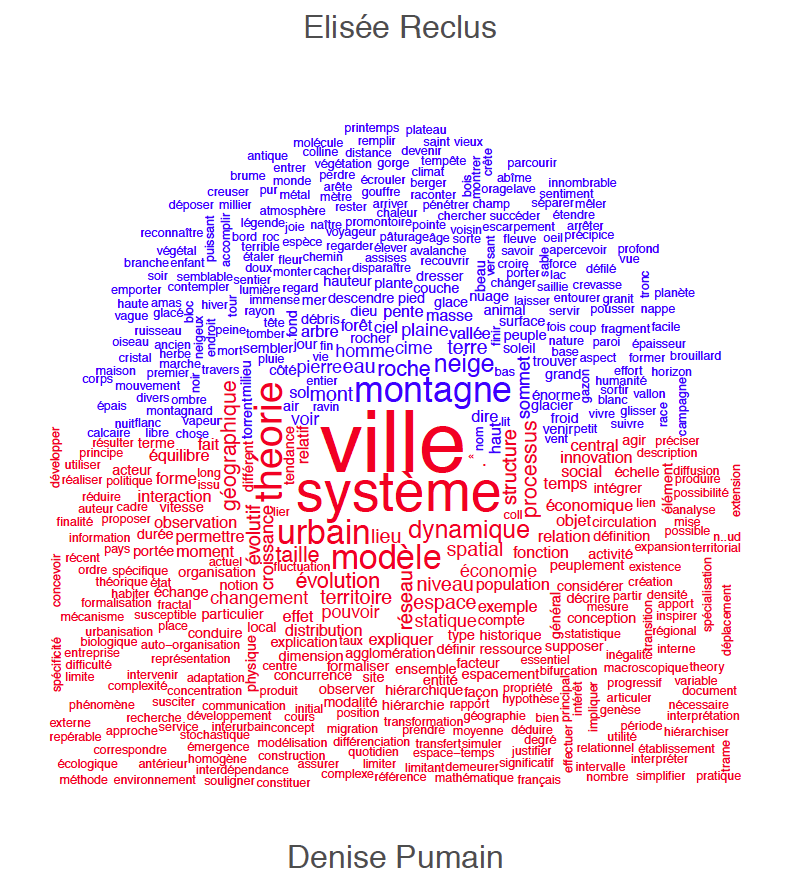
You will find no realistic landscapes prior to the Renaissance. The saints of medieval murals float in a conceptual space informed by hierarchies and symbolic relations; so do those of the Prajñāpāramitā Sūtras. The word “landscape” appears with the Dutch painters of the 15th century. A landscape is a part of the world perceived by […]
Premiers pas avec le module R “Quanteda” pour l’analyse linguistique
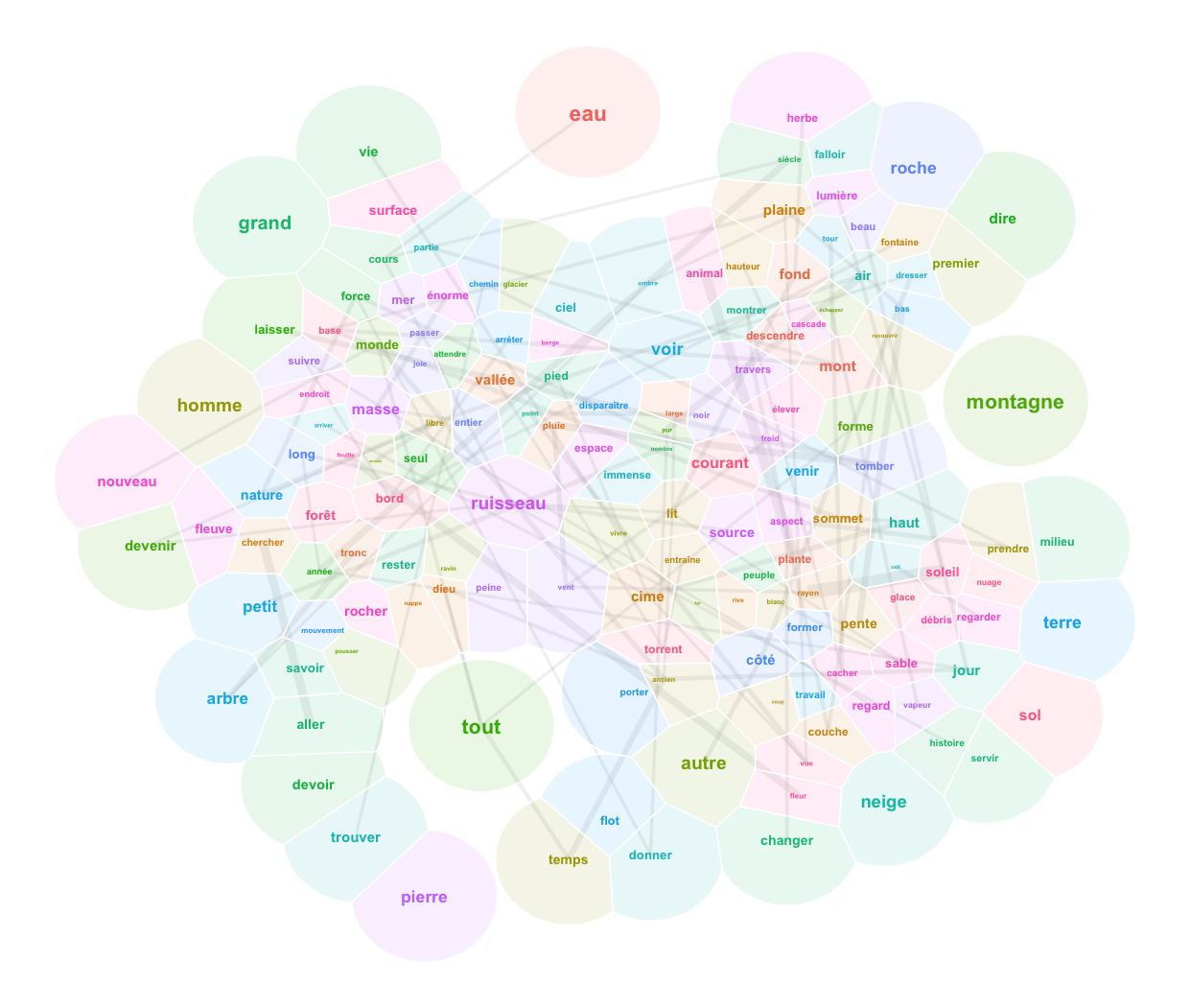
Cet exercice a pour but de vous familiariser avec le module Quanteda pour l’analyse linguistique. Il présuppose que vous avez fait les premiers pas avec R et Rstudio. Installez et activez les modules Installez les modules quanteda, quanteda.textstats, quanteda.textplots, readtext, ggplot2 et udpipe: Créez un nouveau script R pour sauvegarder la progression de votre travail. […]
Text Mining: Detect Strings: Very Fast Word Lookup in a Large Dictionary in R with data.table and matrixStats

Looking up words in dictionaries is the alpha and omega of text mining. I am, for instance interested to know whether a given word from a large dictionary (>100k words) occurs in a sentence or not, for a list of over 1M sentences. The best take at this task is using the Julia language, but […]
Cleaning up PDFs of pre-1990s scanned texts for text mining in R with Quanteda

Text sources are often PDF’s. If optical character recognition (OCR) has been applied, the pdftools R package allows you to extract text from all PDFs to text files stored in a folder. The readtext package converts the set of text files into something useful for Quanteda. Nevertheless, some cleaning is necessary before transforming your text […]