
Ceci est la seconde édition du workshop créé par l’auteur pour le laboratoire d’architecture ALICE (EPFL-ENAC) dans le cadre du projet de recherche et d’enseignement POLIPHILO. Le premier workshop demeure disponible en ligne.
Première partie
Dans cette première partie, nous allons étudier les diverses relations spatiales entre les lieux.
Vos données
Pour la suite de ce workshop, nous partons du principe que vos données se présentent dans un tableau comme celui-ci, stocké dans un fichier Excel:
| geo_image ID | type | date | groupe | latitude | longitude | keyword_u1 | keyword_u2 | keyword_u3 |
| screenshot_200325_meyrinnord_01 | screenshot | 200325 | meyrinnord | 46.17197437926157 | 6.125228052693847 | route | passage | legerete |
| screenshot_200325_meyrinsud_01 | screenshot | 200325 | meyrinsud | 46.17197437926157 | 6.125228052693847 | route | passage | legerete |
| screenshot_200325_meyrinsud_01 | screenshot | 200325 | meyrinsud | 46.219583 | 6.120939 | route | distance | compassion |
| screenshot_200325_meyrinsud_02 | screenshot | 200325 | meyrinsud | 46.217770 | 6.118607 | commun | obstacle | joie |
| screenshot_200325_meyrinsud_03 | screenshot | 200325 | meyrinsud | 46.217247 | 6.117912 | habitat | epaisseur | amertume |
| screenshot_200325_meyrinsud_04 | screenshot | 200325 | meyrinsud | 46.217247 | 6.117912 | habitat | distance | amertume |
| screenshot_200325_meyrinsud_05 | screenshot | 200325 | meyrinsud | 46.216935 | 6.117538 | niveau | creux | honte |
| …. | … | … | … | … | … | … | … | … |
Voir les relations des lieux dans l’espace topographique
Vos données d’origine consistent en une liste de lieux, avec leurs coordonnées topographiques. Vous pouvez visualiser leurs relations topographiques à l’aide d’une carte. Vous avez utilisé qGIS pour faire cela. Il est aussi possible de travailler avec un script, pour une visualisation en ligne interactive. La fenêtre interactive ci-dessous a été générée à l’aide de la bibliothèque JavaScript Leaflet. Cliquez sur les points pour voir les données rattachées à chaque lieu.
Cliquez ici pour voir la carte en pleine page. Si vous souhaitez l’éditer, récupérez son code source (HTML et javascript) à l’aide de votre navigateur et éditez-le. Pour une solution plus facile, sachez également qu’il existe un plugin de qGIS, nommé qgis2web, permettant d’exporter des cartes interactives comme celle-ci.
Pour que le code fonctionne, les données doivent être exportées depuis votre fichier xlsx en format csv et déposées dans un dossier que le code peut trouver; ici : le dossier “data2020”.
Le code utilise les bibliothèques D3.js et Leaflet. Voici l’extrait du code qui récupère les données.
//...
Promise.all([
d3.csv("data2020/poliphilo2020.csv"),
]).then(([pla]) => {
places = pla;
maxlat = d3.max(pla, function(d) { return +d.latitude;} );
maxlon = d3.max(pla, function(d) { return +d.longitude;} );
minlat = d3.min(pla, function(d) { return +d.latitude;} );
minlon = d3.min(pla, function(d) { return +d.longitude;} );
render();
});
//...Code language: JavaScript (javascript)Voir les relations spatiales entre les lieux dans un espace signifiant générique
Les coordonnées de l’espace euclidien ne renvoient pas forcément à des latitudes et longitudes. N’importe quelle variable, soit-elle numérique ou ordinale, peut être placée sur des axes d’un plan euclidien.
Les seules variables que vous avez pour l’heure associé à vos mots clefs sont catégorielles. Il faudrait déterminer s’il existe un ordre pertinent entre les divers mots clefs pour en faire des variables ordinales. Par exemple, cela ferait-il sens de parler d’une échelle évoluant dans cet ordre: joie, légèreté, soulagement, honte, tromperie, colère? On évoluerait donc, plus ou moins, d’un sentiment le plus intensément positif à un sentiment le plus intensément négatif. À vous de décider si cela fait sens. Si ce n’est pas le cas, la ressemblance entre les lieux sera plus intéressante que leur position sur des axes et il est préférable de voir leurs relations sous forme de réseau (section suivante).
Pour l’exercice, nous allons tout de même représenter les données dans un espace significatif générique. Nous travaillerons avec R et l’interface de programmation Rstudio. Installez ces outils, et prenez-les en main avec le tutoriel Premiers pas avec R et Rstudio.
Copiez ensuite le code suivant et exécutez-le. Notez que la fonction read.xlsx("data2020/vos_donnees.xlsx") lit les données d’un fichier Excel en prenant, comme argument, le chemin d’accès vers le fichier en question. Changez l’argument pour indiquer le chemin vers votre fichier depuis votre script. Si le chemin ou le nom du fichier est faux, le code suivant ne marchera pas.
Les fonctions graphiques utilisent le paquet ggplot2.
library(openxlsx)
library(magrittr)
library(data.table)
library(stringr)
library(ggplot2)
library(ggrepel)
library(plotly)
dataimages <- read.xlsx("data2020/200326_ATLAS_DATABASE_meyrinsud.xlsx") %>% as.data.table()
dataimages[,keyword_u1 := trimws(keyword_u1)]
dataimages[,keyword_u2 := trimws(keyword_u2)]
dataimages[,keyword_u3 := trimws(keyword_u3)]
dataimages[,simplename := str_remove(geo_image.ID, "screenshot_200325_")]
dataimages[keyword_u3=="colère",keyword_u3 := "colere"]
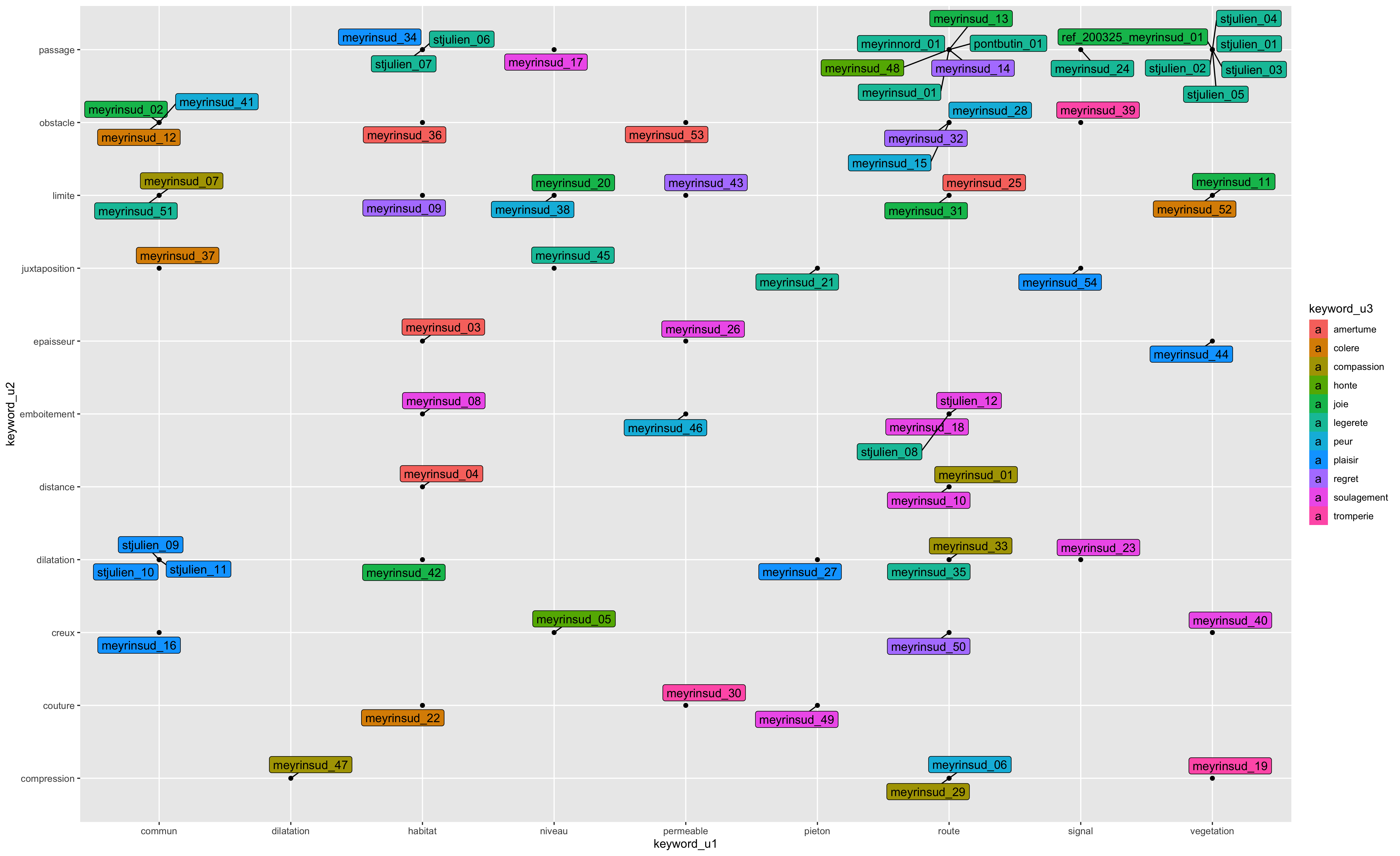
ggplot(dataimages) +
geom_point(aes(x=keyword_u1,y=keyword_u2)) +
geom_label_repel(
aes(x=keyword_u1,y=keyword_u2, label=simplename, fill=keyword_u3)
)
ggsave("data2020/keywords1and2.png", width=18, height=11)
ggplot(dataimages) +
geom_point(aes(x=keyword_u1,y=keyword_u3)) +
geom_label_repel(
aes(x=keyword_u1,y=keyword_u3, label=simplename, fill=keyword_u2)
)
ggsave("data2020/keywords1and3.png", width=18, height=11)
ggplot(dataimages) +
geom_point(aes(x=keyword_u3,y=keyword_u2)) +
geom_label_repel(
aes(x=keyword_u2,y=keyword_u3, label=simplename, fill=keyword_u1)
)
ggsave("data2020/keywords2and3.png", width=18, height=11)Code language: JavaScript (javascript)Ce code génère les trois graphiques suivants:


Réordonner les axes
Il est possible de réordonner les mots clefs dans ggplot2 avec la fonction factor() appliquée sur une variable. Ici, nous réorganisons l’ordre de l’axe comme suit: “colere”, “tromperie”, “honte”, “peur”, “amertume”,”regret”,”compassion”,”soulagement”, “legerete”,”plaisir”, “joie”:
di <- dataimages
di$keyword_u3 <- factor(di$keyword_u3, levels = c("colere", "tromperie", "honte", "peur", "amertume","regret","compassion","soulagement", "legerete","plaisir", "joie"))
ggplot(di) +
geom_point(aes(x=keyword_u2,y=keyword_u3)) +
geom_label_repel(
aes(x=keyword_u2,y=keyword_u3, label=simplename, fill=keyword_u1)
)
ggsave("data2020/keywords2and3_reordered.png", width=18, height=11)Code language: PHP (php)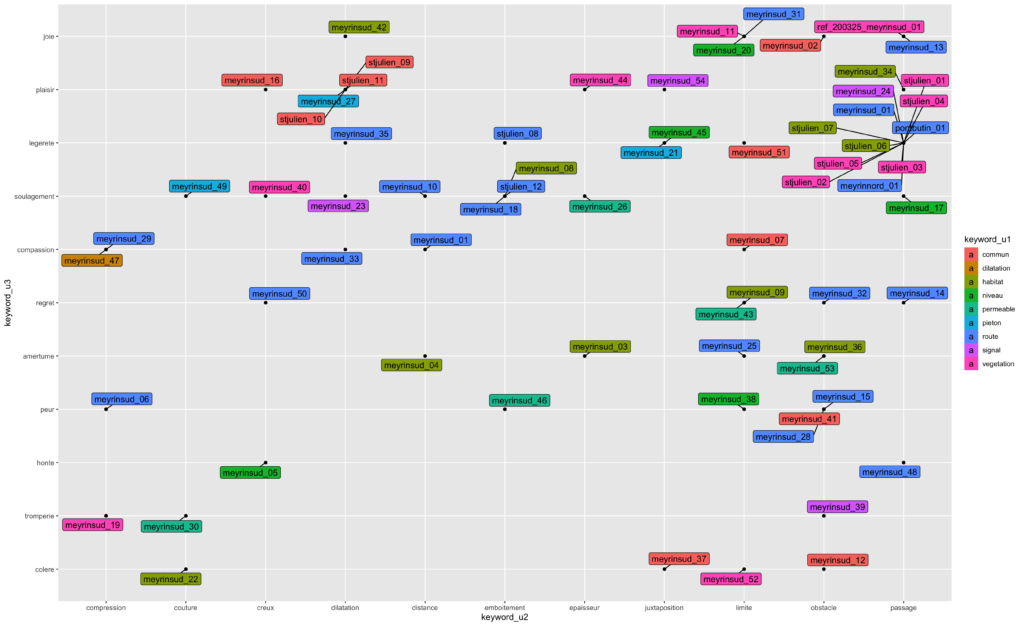
De nouveau, à vous de décider si cette transformation de variables catégorielles en variables ordinales fait sens.
Voir 3 variables (types de mots clefs) dans 3 dimensions
En outre, comme vous pouvez le constater, il n’est pas possible de mapper trois variables (c’est-à-dire les trois types de mots clefs) dans un espace à 2 dimensions, à moins d’utiliser la variable visuelle “couleur”. Pour voir les trois variables dans un seul espace, il est possible d’utiliser la 3e dimension. Le code R suivant…
fig <- plot_ly(
x=dataimages$keyword_u1,
y=dataimages$keyword_u2,
z=dataimages$keyword_u3,
type="scatter3d",
mode="markers",
text=dataimages$simplename
) %>% layout(
title = "Mots clefs",
scene = list(
xaxis = list(
title = 'keyword_u1',
autotick = F,
dtick = 1
),
yaxis = list(
title = 'keyword_u2',
autotick = F,
dtick = 1
),
zaxis = list(
title = 'keyword_u3',
autotick = F,
dtick = 1,
categoryarray = c("colere", "tromperie", "honte", "peur", "amertume","regret","compassion","soulagement", "legerete","plaisir", "joie"),
categoryorder = "array"
)
)
)
fig
htmlwidgets::saveWidget(fig, "espace_signifiant.html")Code language: PHP (php)…produit la figure interactive suivante
À vous de décider si elle est plus lisible… Dans tous les cas, elle ne ferait du sens que si vos variables catégorielles peuvent être repensées en termes de variables ordinales.
Voir les relations des lieux sous forme de réseau
Transformation des données
Vos données d’origine attribuent trois mots clefs à chaque lieu. Nous considérerons le partage de mots clefs comme un lien entre deux lieux. En d’autres mots: deux lieux qui partagent le même mot clef sont liés. Afin de pouvoir penser de cette manière, il est nécessaire de transformer vos données.
Si vous avez trop de difficultés avec la marche à suivre de cette section, téléchargez directement le fichier edges.csv et rapportez-vous à la section suivante (visualisez le réseau).
Mais essayez avant. Nous travaillerons avec R et l’interface de programmation Rstudio. Si ce n’est pas déjà fait, installez ces outils, et prenez-les en main avec le tutoriel Premiers pas avec R et Rstudio.
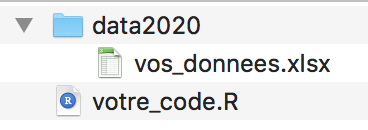
Déposez le fichier Excel contenant vos données dans un dossier nommé par exemple “data2020”. Ouvrez Rstudio et créez un nouveau script R. Sauvegardez directement ce script dans le dossier parent du dossier data2020. Vous devriez avoir la structure de fichiers et dossiers suivante:
Copiez le code ci-après dans votre code et exécutez-le. Notez que la fonction read.xlsx("data2020/vos_donnees.xlsx") lit les données d’un fichier Excel en prenant, comme argument, le chemin d’accès vers le fichier en question. Si le chemin ou le nom du fichier est faux, le code suivant ne marchera pas. Modifiez donc cet argument si vous avez déposé le fichier ailleurs ou que vous avez donné un autre nom:
library(openxlsx)
library(magrittr)
library(data.table)
library(stringr)
dataimages <- read.xlsx("data2020/vos_donnees.xlsx") %>% as.data.table()
# Le lignes suivantes servent uniquement à nettoyer les données. Enlever, par exemple, les espaces excédentaires. En informatique "compassion" ≠ "compassion ".
dataimages[,keyword_u1 := trimws(keyword_u1)]
dataimages[,keyword_u2 := trimws(keyword_u2)]
dataimages[,keyword_u3 := trimws(keyword_u3)]
dataimages[,simplename := str_remove(geo_image.ID, "screenshot_200325_")]
dataimages[keyword_u3=="colère",keyword_u3 := "colere"]
source_target <- data.table(
source = character(),
target = character(),
relation = character(),
relationtype = character()
)
uniques <- list(
unique(dataimages$keyword_u1),
unique(dataimages$keyword_u2),
unique(dataimages$keyword_u3)
)
for (i in 1:3){
for (j in 1:length(uniques[[i]])){
print(paste(i, j))
if (is.na(uniques[[i]][j])) {break}
if (i==1) ulinks <- dataimages[keyword_u1==uniques[[i]][j]]$simplename
if (i==2) ulinks <- dataimages[keyword_u2==uniques[[i]][j]]$simplename
if (i==3) ulinks <- dataimages[keyword_u3==uniques[[i]][j]]$simplename
combinations <- combn(ulinks,2) %>% t
combinations <- data.table(
source = combinations[,1],
target = combinations[,2],
relation = uniques[[i]][j],
relationtype = paste0("u",i)
)
source_target <- rbindlist(list(source_target,combinations))
}
}
fwrite(source_target, "data2020/edges.csv")Code language: PHP (php)Le dossier data2020 devrait désormais contenir le fichier “edges.csv” contenant les données transformées dans la forme suivante:
| source | target | relation | relationtype |
| meyrinnord_01 | meyrinsud_01 | route | u1 |
| meyrinnord_01 | meyrinsud_01 | route | u1 |
| meyrinnord_01 | meyrinsud_06 | route | u1 |
| meyrinnord_01 | meyrinsud_10 | route | u1 |
| meyrinnord_01 | meyrinsud_13 | route | u1 |
| meyrinnord_01 | meyrinsud_14 | route | u1 |
| meyrinnord_01 | meyrinsud_15 | route | u1 |
| meyrinnord_01 | meyrinsud_18 | route | u1 |
| meyrinnord_01 | meyrinsud_25 | route | u1 |
| … | … | … | … |
Vous avez une matrice source-target (origines-destinations) permettant de construire un réseau.
Visualisez le réseau
Pour visualiser le réseau, nous utiliserons le logiciel Cytoscape. Pour le prendre en main, suivez le tutoriel Visualiser des réseaux géographiques; et notamment la partie “Importer les données CSV“. Alternativement, si vous vous sentez à l’aise, installez simplement Cytoscape et suivez vos intuitions.
Importez le fichier edges.csv – que vous venez de créer ou de télécharger – dans Cytoscape. Utilisez les fonctions apprises dans le tutoriel ou vos intuitions d’usage de logiciel informatique pour obtenir la représentation suivante.

Cytoscape permet d’étudier le réseau plus finement. Disons que nous nous intéressons uniquement aux lieux portant le mot clef “route”. Sélectionnons d’abord tous les liens “route”:
Sélectionnons ensuite les nœuds reliés par le lien “route” (en d’autres termes, les lieux qui ont ce mot clef):
Avec ces nœuds sélectionnés, cliquez sur le bouton “New Network from Selection“.
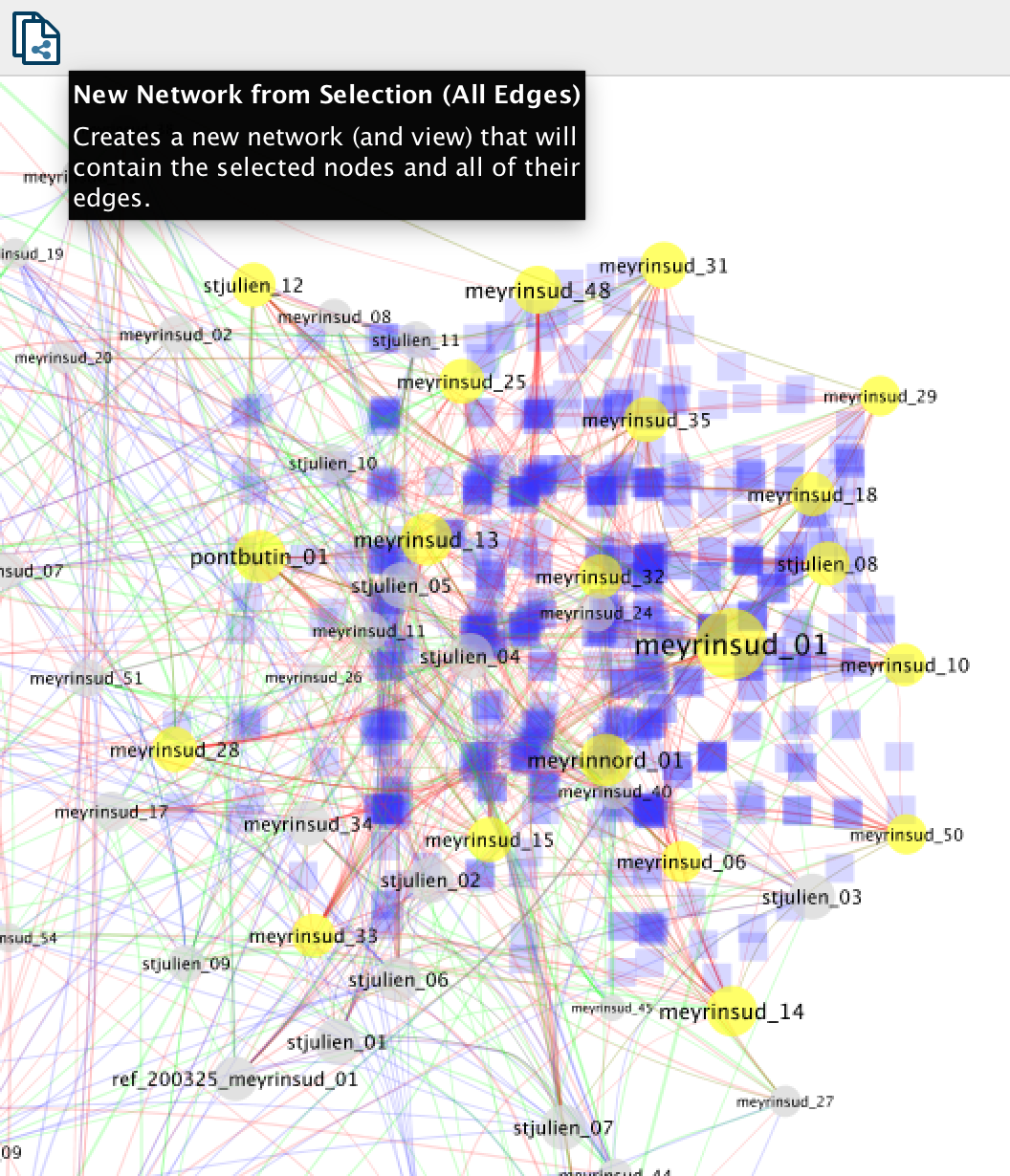
Vous obtenez un nouveau sous-réseau focalisé sur les relations thématiques entre lieux déjà liés par la relation thématique “route”. Cliquez sur l’image pour l’agrandir.
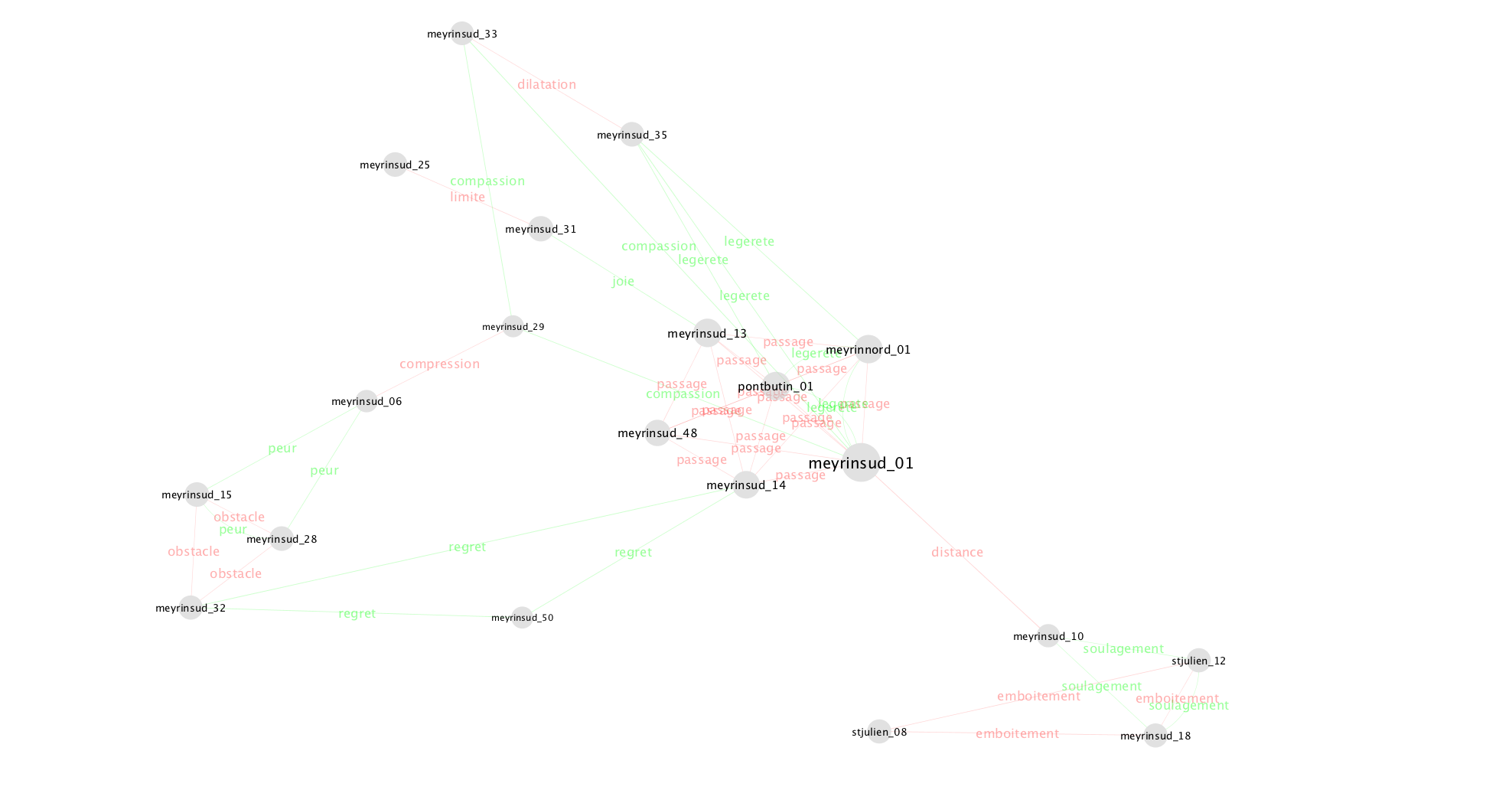
Défi: créez un sous-réseau qui ne montre que les relations de type u2 (relationtype = u2).
Si vous avez eu de la difficulté avec cette marche à suivre, le résultat du traitement peut être téléchargé directement; le fichier image_keyword_network.cys peut être ouvert avec Cytoscape.
Ajouter des images aux nœuds
Cytoscape vous permet d’utiliser des images comme marqueurs des nœuds d’un réseau. Cette fonctionnalité est décrite dans un autre article.
Vers la seconde partie
Continuer les workshop avec la seconde partie.