Cet exercice a pour but de vous familiariser avec le module Quanteda pour l’analyse linguistique. Il présuppose que vous avez fait les premiers pas avec R et Rstudio.
Installez et activez les modules
Installez les modules quanteda, quanteda.textstats, quanteda.textplots, readtext, ggplot2 et udpipe:
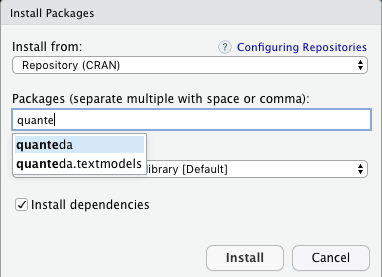
Créez un nouveau script R pour sauvegarder la progression de votre travail. Ajoutez les lignes suivantes à votre script et exécutez-les pour activer les quatre modules que vous venez d’installer:
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(readtext)
library(ggplot2)
library(udpipe)Code language: CSS (css)Le deuxième module, readtext, sert à extraire des textes de n’importe quel document (fichier txt, Word, PDF…) et à le stocker dans la mémoire de votre ordinateur sous une forme directement exploitable par Quanteda.
Le module ggplot2 nous permettra d’afficher un diagramme en barres de la fréquence des mots.
Le quatrième module, nommé udpipe nous servira à la lemmatisation dans la partie avancée de cet exercice.
Un exemple basique
Un vecteur de textes
Pour se familiariser avec le processus d’analyse Quanteda, prenons un exemple simple de deux textes stockés dans un vecteur de textes.
textes <- c("Ceci est un premier exemple de texte.",
"Ceci est un second exemple de texte."
)
textesCode language: JavaScript (javascript)La dernière ligne, textes, demande à R d’afficher le contenu de la variable textes. Vous devriez voir ceci:

Un corpus de textes
Transformons le vecteur de textes dans un corpus de textes. Un objet “corpus” est similaire à un vecteur de textes, mais il possède une structure mieux exploitable par Quanteda.
moncorpus <- corpus(textes)
moncorpus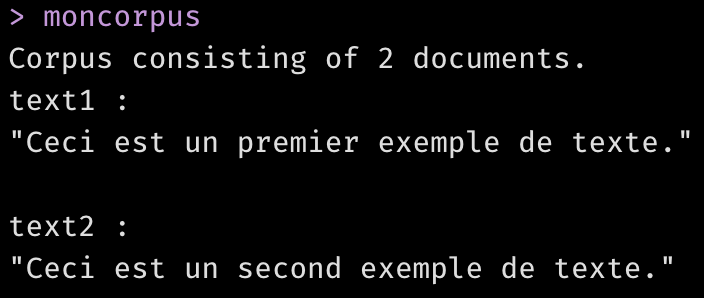
Comme vous le voyez, dans un corpus de textes quanteda, chaque texte est désigné par le terme “document“, quelle que soit sa longueur. Ainsi, vous avez un corpus de deux documents consistant chacun d’une seule phrase.
Chaque document porte un nom que vous pouvez assigner, comme nous le ferons plus tard. Dans cet exemple simple, Quanteda a automatiquement nommé les documents “text1” et “text2”. La fonction summary() vous donne un résumé statistique du corpus, avec le décompte de “tokens” (mots ou signes de ponctuation individuels) et de phrases dans chaque document:
summary(moncorpus)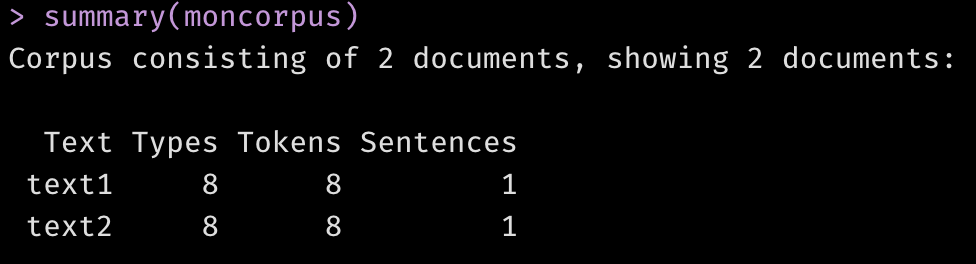
La “tokenisation”
La tokenisation sépare chaque texte en mots individuels en se basant sur des séparateurs comme les espaces. Les signes de ponctuation sont a priori considérés comme des tokens, mais ils peuvent aussi être considérés comme des séparateurs au même titre que les espaces, ou simplement éliminés; nous verrons cela plus tard.
mestokens <- tokens(moncorpus)
mestokens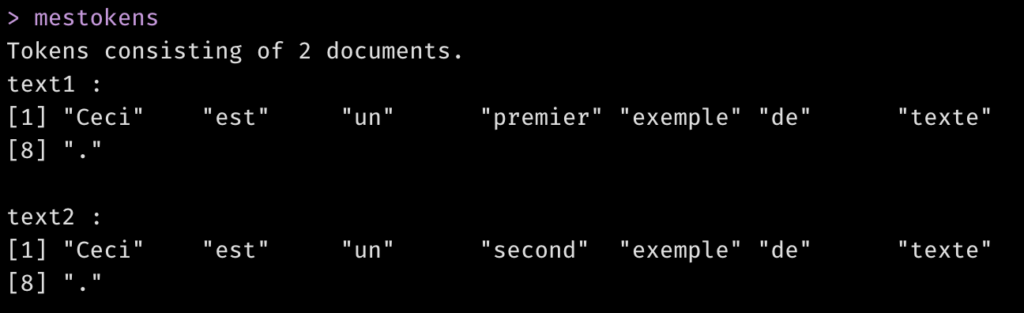
Ce partitionnement en tokens permet de faire des analyses statistiques, comme par exemple constituer une matrice document-feature.
La matrice document-feature (DFM)
Une document-feature matrix (DFM) liste les mots (les features) en colonnes et les documents en lignes. Quanteda utilise le terme générique “features” car les colonnes d’une DFM peuvent être aussi bien des tokens que des expressions entières, ou des suites de n mots, nommées n-grammes. Dans notre exemple simple, nos features sont des mots individuels. La DFM donne la fréquence d’un mot donné dans chaque document.
madfm <- dfm(mestokens)
madfm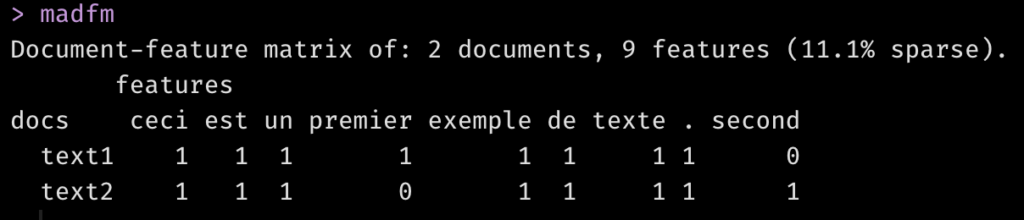
Ces matrices document-feature peuvent être immenses si vous avez de nombreux mots différents dans de nombreux documents. Quanteda optimise l’usage de la mémoire de votre ordinateur en les stockant sous forme de “matrices creuses” (sparse matrix). Il n’est pas nécessaire de comprendre le concept de matrice creuse pour travailler avec Quanteda; je le note ici seulement pour que vous sachiez pourquoi le programme indique “11.1% sparse“. L’information importante est que vous avez 2 documents avec 9 mots (features) distincts.
Résumé des fréquences des mots
La fonction textstat_frequency() appliquée à la DFM vous donne la fréquence d’occurrence de chaque mot sur l’ensemble des textes (frequency) et le nombre de documents dans lequel ce mot apparaît (docfreq).
mesfrequences <- textstat_frequency(madfm)
mesfrequences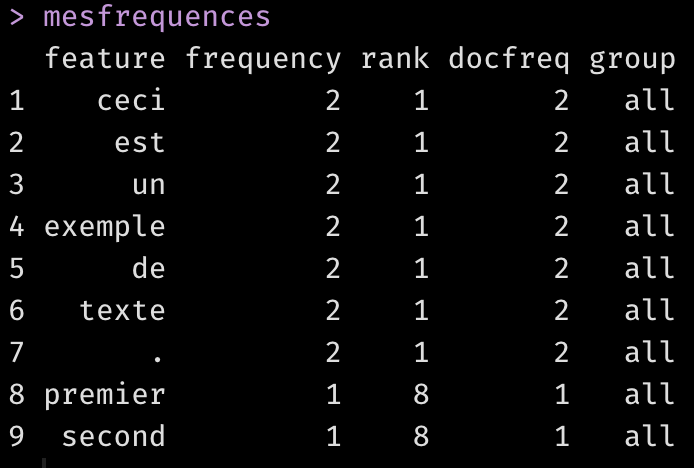
On voit que deux mots, “premier” et “second” apparaissent dans un seul document. Les autres mots apparaissent tous dans tous les documents. Vous pouvez afficher la fréquence totale de mots sous forme d’un diagramme à barres:
ggplot(mesfrequences) +
geom_bar(aes(x=reorder(feature,frequency),y=frequency),stat="identity")+
coord_flip()Code language: JavaScript (javascript)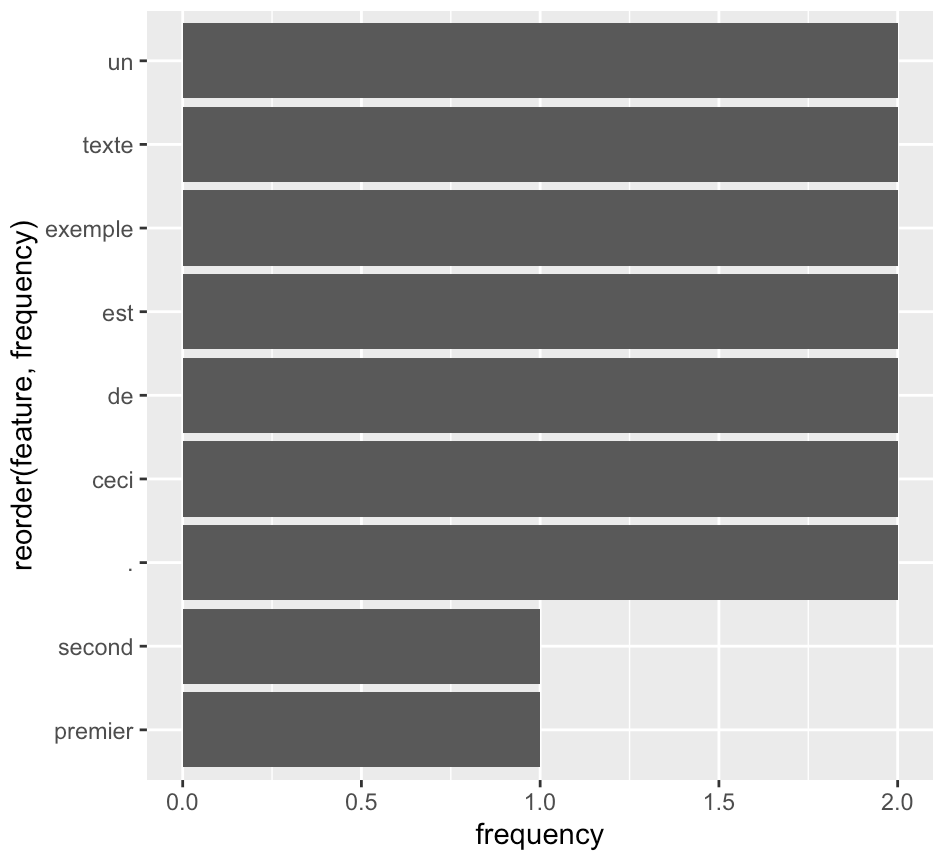
Pour une étude de nombreux mots, je recommande le digramme à barres, qui permet également des comparaisons exactes. Nous avons utilisé ce type de diagrammes dans l’article suivant:
- Ourednik, A., Koller, G., Fleer, P., & Nellen, S. (2018). Feeling Like a State. The Sentiments-tide of Swiss Diplomacy through the Eye of the Algorithm. Administory. Zeitschrift Für Verwaltungsgeschichte, 3(1). https://doi.org/10.2478/ADHI-2018-0044
Mais il peut être plus convivial dans certains cas d’utiliser un nuage de mots.
Le nuage de mots (wordcloud)
Le nuage de mots est une autre représentation graphique du résumé des fréquences de mots.
textplot_wordcloud(madfm,min_count = 1)
Un exemple plus avancé
Récupérer des fichiers de texte depuis le web
Dans la suite de cet exercice, nous allons utiliser Quanteda pour analyser deux textes plus conséquents:
- Reclus, Elisée (1876). Histoire d’une Montagne. Paris: Bibliothèque d’éducation et de récréation J. Hetzel, http://www.gutenberg.org/ebooks/60850
- Pumain, Denise (1997). Pour une théorie évolutive des villes. Espace Geographique, 26(2), 119‑134. https://doi.org/10.3406/spgeo.1997.1063
Nous récupérons ces textes directement de l’internet et les stockons dans la variable “textes”. Notez que, pour charger des fichiers stockés sur votre ordinateur avec la fonction readtext(), il suffit de remplacer les adresses web par des adresses de fichiers sur votre ordinateur.
textes <- readtext(c(
"http://www.gutenberg.org/files/60850/60850-0.txt",
"https://hal.archives-ouvertes.fr/hal-01760576/file/spgeo_0046-2497_1997_num_26_2_1063.pdf"
)) Code language: JavaScript (javascript)Le corpus
Nous allons ensuite créer un “corpus” quanteda contenant ces deux textes.
moncorpus <- corpus(textes)
summary(moncorpus)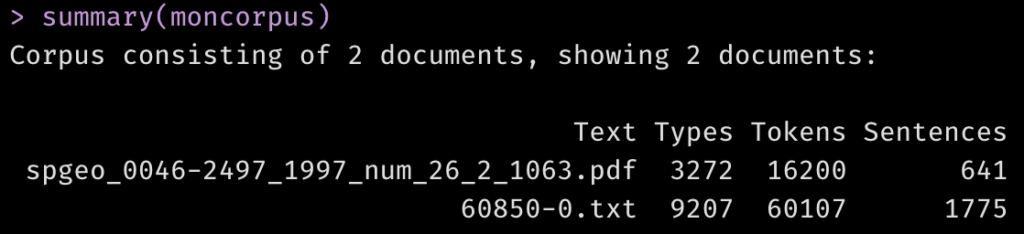
Vous constatez que les documents portent le nom des fichiers dont les textes ont été extraits. Nous pouvons améliorer cela en renommant les documents du corpus:
docnames(moncorpus) <- c("Denise Pumain","Elisée Reclus")
summary(moncorpus)Code language: JavaScript (javascript)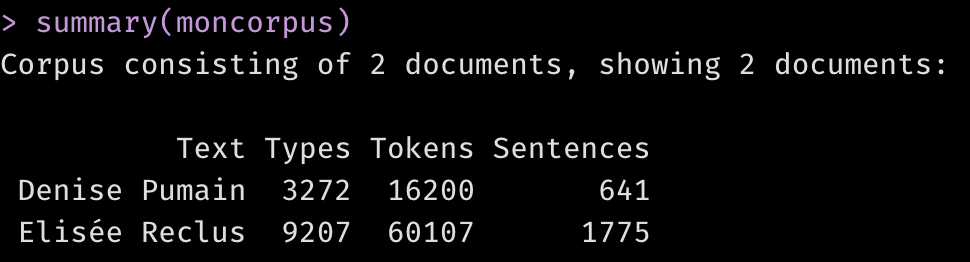
Regardez de plus près le résultat de la fonction summary(). Lequel des deux documents est plus long? À quoi faudra-t-il faire attention en comparant, par exemple, leur diversité lexicale?
Tokenizasion
Nous allons tokeniser ce corpus. Ce faisant, nous allons enlever quelques éléments qui ne nous intéressent pas dans un nuage de mots, comme les signes de ponctuation ou les nombres. Comme l’indique la documentation de Quanteda, on peut spécifier cela dans la fonction tokens()avec les paramètres suivants:
- remove_punct : si
TRUE, enlève tous les caractères de type Unicode “Punctuation” [P] - remove_symbols : si
TRUE, enlève tous les caractères de type Unicode “Symbol” [S] - remove_numbers : si
TRUE, enlève tous les tokens qui ne consistent qu’en nombres, mais pas les mots qui commencent par un nombre, p.ex. “2day”
Essayez l’effet de ces paramètres avec une seule ligne de texte:
montexte <- "La tokenisation sépare le texte en mots individuels en se basant sur des séparateurs comme les espaces, 123, 10$, les virgules, les points etc."
# Essayez d'abord ceci:
mestokens <- tokens(montexte)
mestokens[[1]]
# Et ensuite cela:
mestokens <- tokens(montexte, remove_punct = TRUE, remove_symbols = TRUE, remove_numbers = TRUE)
mestokens[[1]] Code language: PHP (php)À présent, tokenisons les textes de notre corpus:
mestokens <- tokens(moncorpus, remove_punct = TRUE, remove_symbols = TRUE, remove_numbers = TRUE)
mestokensCode language: HTML, XML (xml)Constituer la DFM et produire un premier nuage de mots
madfm <- dfm(mestokens)
textplot_wordcloud(madfm)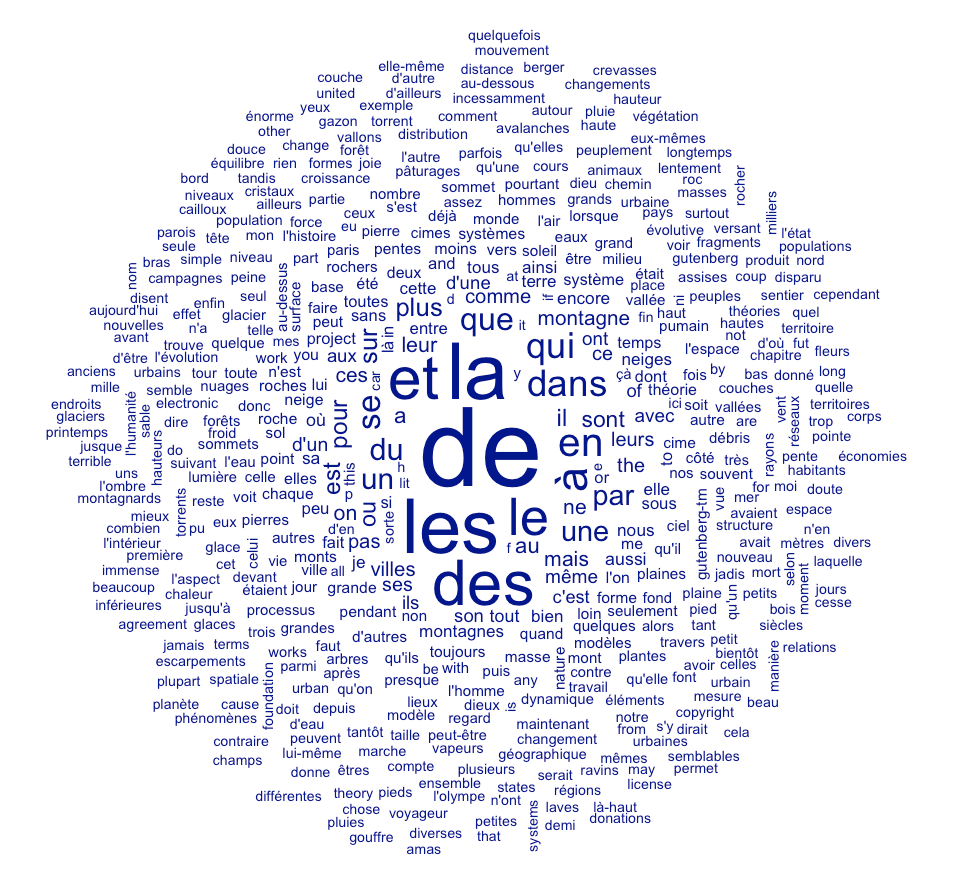
Enlever les “stopwords“
Comme vous le voyez, les mots comme de, la, les, et etc. dominent. Ces mots ne sont pas très intéressants car fréquents dans n’importe quel texte. Pour cette raison, on les appelle des “stopwords“. Il faut les enlever. Quanteda met déjà à disposition une liste de stopwords français. Affichez cette liste en exécutant la commande suivante:
stopwords("fr")Code language: JavaScript (javascript)À présent, enlevons-les:
madfm <- dfm_remove(madfm, stopwords("fr"))
textplot_wordcloud(madfm)Code language: JavaScript (javascript)
Améliorer le découpage des tokens
Comme vous le voyez, des stopwords avec des apostrophes “c’est”, “d’un”, “qu’on” etc. n’ont pas été enlevés. Le problème est que la tokenisation n’a pas considéré l’apostrophe comme un séparateur mais comme une partie du mot. Remédions-y en modifiant l’objet mestokens:
mestokens <- tokens_split(mestokens,"'")Code language: JavaScript (javascript)Nous devons recréer la DFM avec cette liste de tokens adaptée. De nouveau, on enlève les stopwords français, puis on crée un nuage de mots basé sur ces nouvelles données:
madfm <- dfm(mestokens)
madfm <- dfm_remove(madfm, stopwords("fr"))
textplot_wordcloud(madfm)Code language: JavaScript (javascript)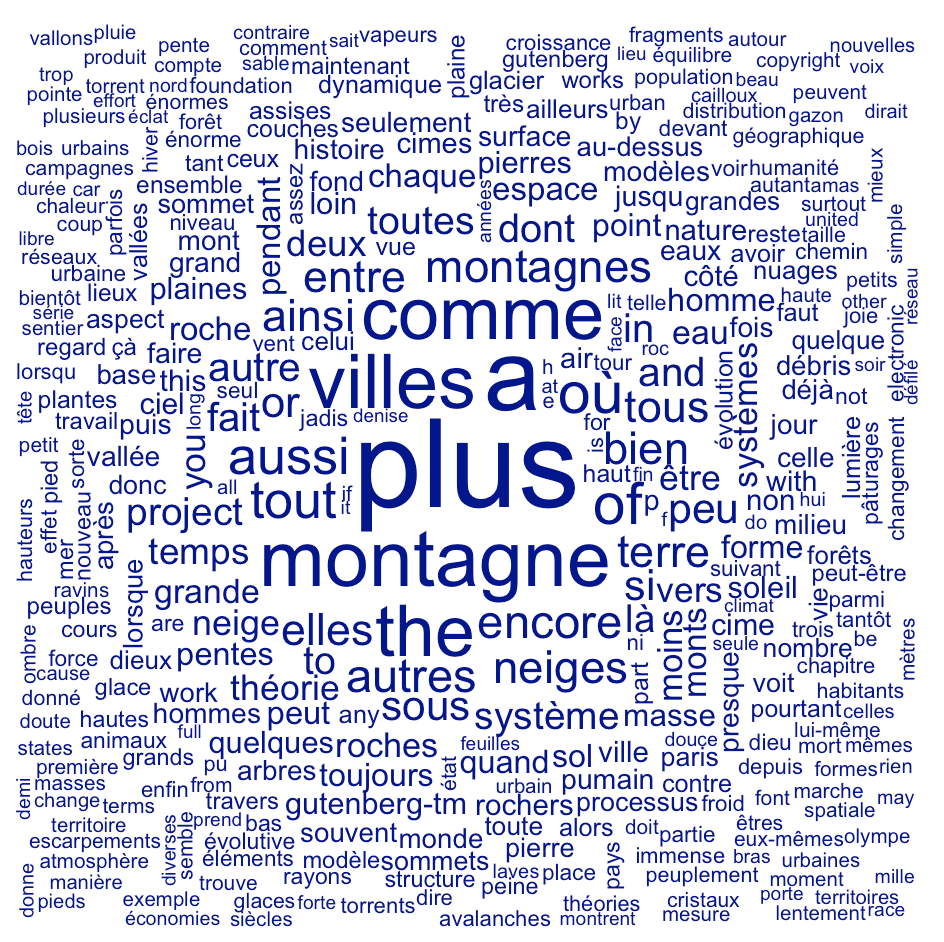
Changer la liste des mots exclus
Comme vous le voyez, des mots peu intéressants comme “plus”, “the”, “encore” etc. persistent. Il faut élargir notre liste de stopwords. Comme certains mots communs en anglais apparaissent, nous allons aussi profiter d’inclure la liste prédéfinie de stopwords anglais dans notre liste de mots à enlever. Vous pouvez ajouter de mots à cette liste en regardant le nuage de mots résultant et en choisissant vous-mêmes les mots qui ne vous intéressent pas.
Nous allons aussi enlever les lettres isolées (a, b, c, d,…). Pour s’éviter de tapper chaque lettre individuelle, on peut utiliser pour cela l’objet letters préstocké dans R. Pour comprendre, examinez cet objet en écrivant la ligne ci-dessous dans la console et en pressant “Enter”:
lettersÀ présent, enlevons tous les tokens dont nous n’avons pas besoin:
mots_a_enlever <- c(stopwords("fr"), stopwords("en"),letters, "comme","plus","où","tout","entre","elles","ainsi","aussi","si","dont","sous","dont","là","work","non","encore","celle","celles","ni","gutenberg-tm","gutenberg","quelques","donc","selon","carré","autre","autres","çà","être","quand","denise","works","car","très","celui","chaque","tel","puis","ceux","moins","uns","jusqu","jusque","peu","full","deux","pourtant","vers","enfin","pumain", "élysée","reclus","avoir","p.h.","th","huriot","après","va","peut","béguin","j.m","priori","al","certains","dir","suivant","rien","toujours","doit","part")
madfm <- dfm_remove(madfm, mots_a_enlever)
textplot_wordcloud(madfm)Code language: JavaScript (javascript)
Comparer deux textes
Jusqu’ici, l’occurrence des mots était considérée sur l’ensemble des deux textes. Pour les comparer, il faut indiquer à Quanteda de les considérer de manière séparée, en créant des groupes dans la DFM à l’aide de la fonction dfm_group() et en spécifiant qu’il faut comparer ces groupes en ajoutant le paramètre comparison=TRUE dans la fonction textplot_wordcloud() :
madfm <- dfm_group(madfm, groups=docnames(madfm))
textplot_wordcloud(madfm, comparison=TRUE)Code language: HTML, XML (xml)
Les contraste n’est pas optimal. Nous pouvons modifier les couleurs avec le paramètre color:
textplot_wordcloud(madfm, comparison=TRUE, color=c("red","blue"))Code language: PHP (php)
Le stemming
On pourrait se satisfaire de cette dernière variante du wordcloud. Vous constatez néanmoins que certains mots très similaires comme “système” et “systèmes” apparaissent comme deux mots séparés. Ceci est gênant pour l’analyse sémantique des deux textes. Une façon d’y remédier est la racinisation (stemming) qui consiste à réduire tous les mots à leur racine:
mestokens2 <- tokens_wordstem(mestokens,language = "fr")
madfm <- dfm(mestokens2,groups = docnames(mestokens))
madfm <- dfm_remove(madfm, mots_a_enlever)
textplot_wordcloud(madfm, comparison=TRUE, color=c("blue","red"))Code language: PHP (php)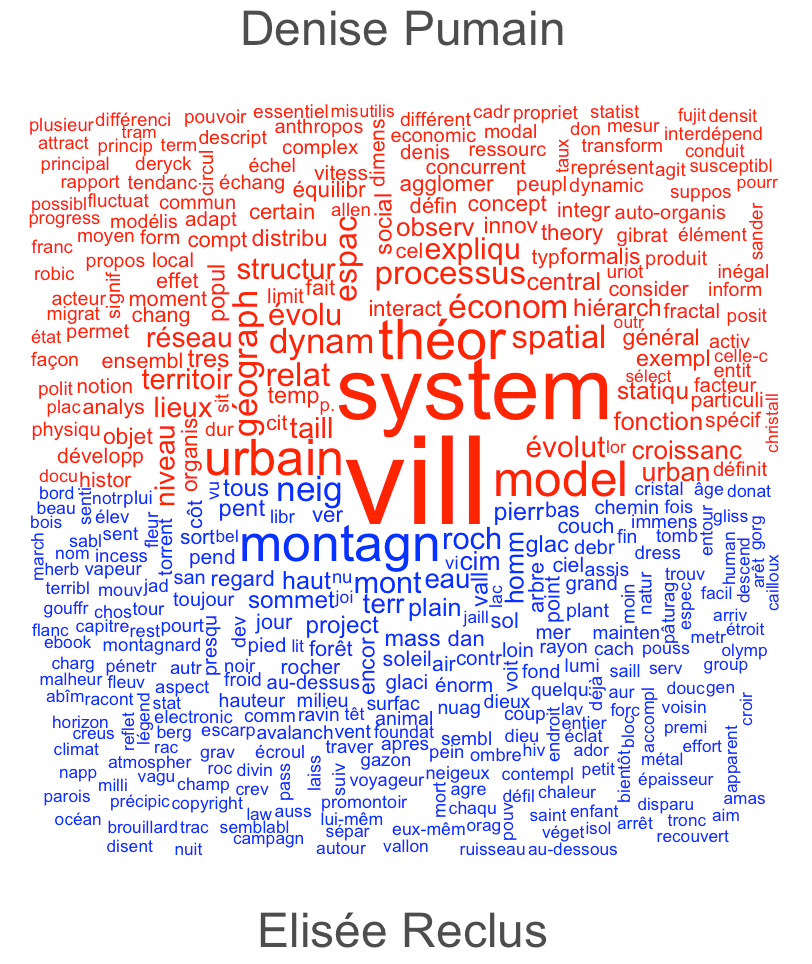
Le résultat rassemble les mots partageant la même racine, mais il est moins convivial pour le lecteur du nuage de mots.
Lemmatisation
Une alternative, plus complexe, est la lemmatisation, qui réduit les flexions des mots aux lemmes. Les flexions sont les différentes formes fléchies d’un même mot. Les formes fléchies correspondent aux formes conjuguées ou accordées d’un mot de base : le lemme. Par exemple, le mot “jouer”, verbe à l’infinitif ni accordé, ni conjugué est un lemme. Il possède différentes flexions qui correspondent à ses formes conjuguées à diverses personnes et temps : “jouera” , “jouons” , “joué”… Un autre exemple: le mot “montagne” correspond à la forme non accordée et donc au lemme des flexions accordées “montagne” et “montagnes”.
Quanteda ne possède pas d’algorithme de lemmatisation et il faut donc se tourner vers un autre outil. L’un des plus connus s’appelle TreeTagger. Il s’agit d’un logiciel en ligne de commande développée par l’université de Munich. Il ne lemmatise pas seulement mais détecte les “parts-of-speech“, c’est-à-dire détecte pour chaque mot s’il s’agit d’un adjectif, d’un nom, d’un adverbe etc. Vous pouvez installer TreeTagger sur vos machines et le connecter à R. Son installation est plutôt complexe, néanmoins. Une alternative plus conviviale est l’outil UD-Pipe développé par l’institut de linguistique appliquée de l’Université Charles de Prague. Cet outil est disponible sous forme d’un module R nommé udpipe, facile à installer.
Au début de cet exercice, vous avez déjà téléchargé et activé le module udpipe. Il faut à présent télécharger un modèle de lemmatisation. Ces modèles prennent ~20MB chacun sur le disque dur et sont différents pour chaque langue. Comme nous travaillons en français, nous allons télécharger le module français. La commande suivante s’en occupe:
udmodel <- udpipe_download_model(language = "french") Code language: HTML, XML (xml)Si et seulement si la commande ci-dessus ne marche pas en raison d’une interruption du réseau, vous pouvez obtenir une copie du modèle français à partir de mon site avec les deux commandes suivantes:
download.file("https://ourednik.info/unine/french-gsd-ud-2.5-191206.udpipe", "french-gsd-ud-2.5-191206.udpipe")
udmodel <- udpipe_load_model("french-gsd-ud-2.5-191206.udpipe")Code language: JavaScript (javascript)Testez si udpipe fonctionne avec un exemple de texte:
udpipe("Ceci est un exemple de texte.", object=udmodel)Code language: JavaScript (javascript)Vous devriez voir un tableau comme celui-ci, avec une colonne, notamment, dédiée au lemme de chaque mot. Notez que udpipe identifie aussi le type de chaque token (pronom, nom, déterminant…). Ceci nous permet de nous passer d’une liste de stopwords si nous ne conservons que les noms, les verbes et les adjectifs :
| token_id | token | lemma | upos | feats | head_token_id | dep_rel | misc |
| 1 | Ceci | ceci | PRON | Number=Sing | 4 | nsubj | |
| 2 | est | être | AUX | Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin | 4 | cop | |
| 3 | un | un | DET | Definite=Ind|Gender=Masc|Number=Sing|PronType=Art | 4 | det | |
| 4 | exemple | exemple | NOUN | Gender=Masc|Number=Sing | 0 | root | |
| 5 | de | de | ADP | 6 | case | ||
| 6 | texte | texte | NOUN | Gender=Masc|Number=Sing | 4 | nmod | SpaceAfter=No |
| 7 | . | . | PUNCT | 4 | punct | SpacesAfter=\n |
Ensuite, exécutez le code suivant pour obtenir un wordcloud lemmatisé:
getlemma <- function(x) {
ttg <- udpipe(x,object = udmodel)
ttg <- ttg[ttg$upos %in% c("NOUN","VERB","ADJ"),]
return(paste(ttg$lemma, collapse=" "))
}
mestexteslemmatises <- lapply(textes$text,getlemma)
mestokens3 <- quanteda::tokens(unlist(mestexteslemmatises))
docnames(mestokens3) <- c("Denise Pumain"," Elisée Reclus")
madfm <- dfm(mestokens3,groups = docnames(mestokens3))
madfm <- dfm_remove(madfm, mots_a_enlever)
textplot_wordcloud(madfm, comparison=TRUE, color=c("blue","red"))Code language: PHP (php)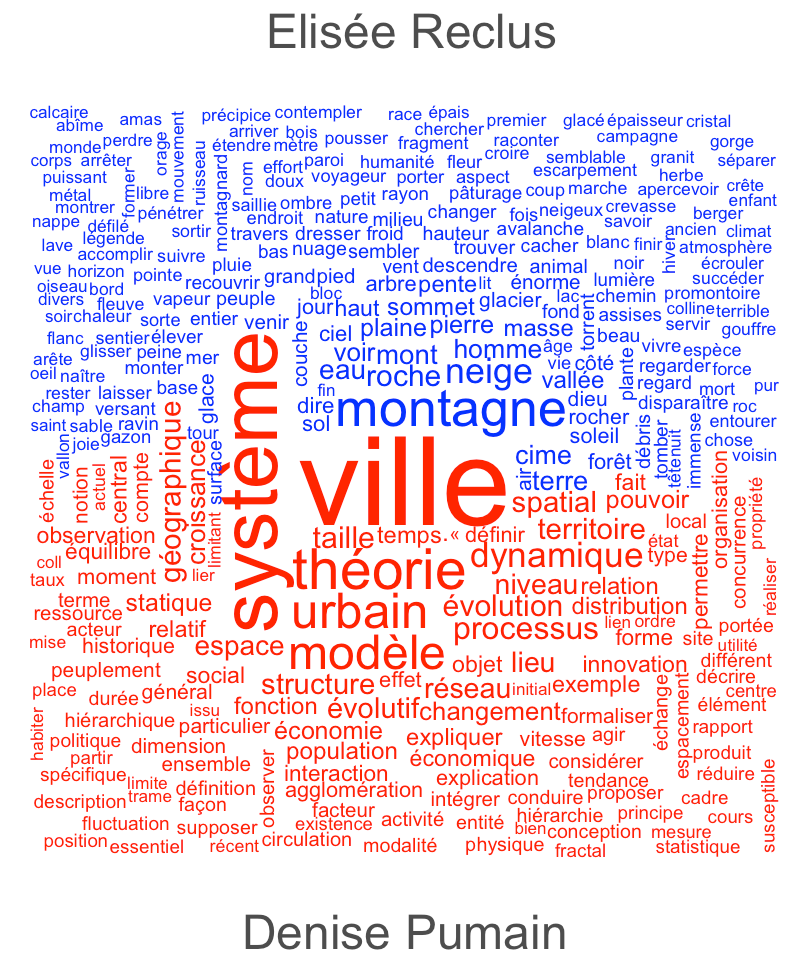
Exporter le Wordcloud en pdf
Au lieu d’imprimer le wordcloud dans l’interface RStudio, vous pouvez l’imprimer dans un fichier, portant par exemple le titre wordcloud2.pdf:
pdf("wordcloud2.pdf")
textplot_wordcloud(madfm, comparison=TRUE, color=c("blue","red"))
dev.off()Code language: PHP (php)Cela vous permettra d’éditer l’image, par exemple avec Inkscape ou Illustrator.
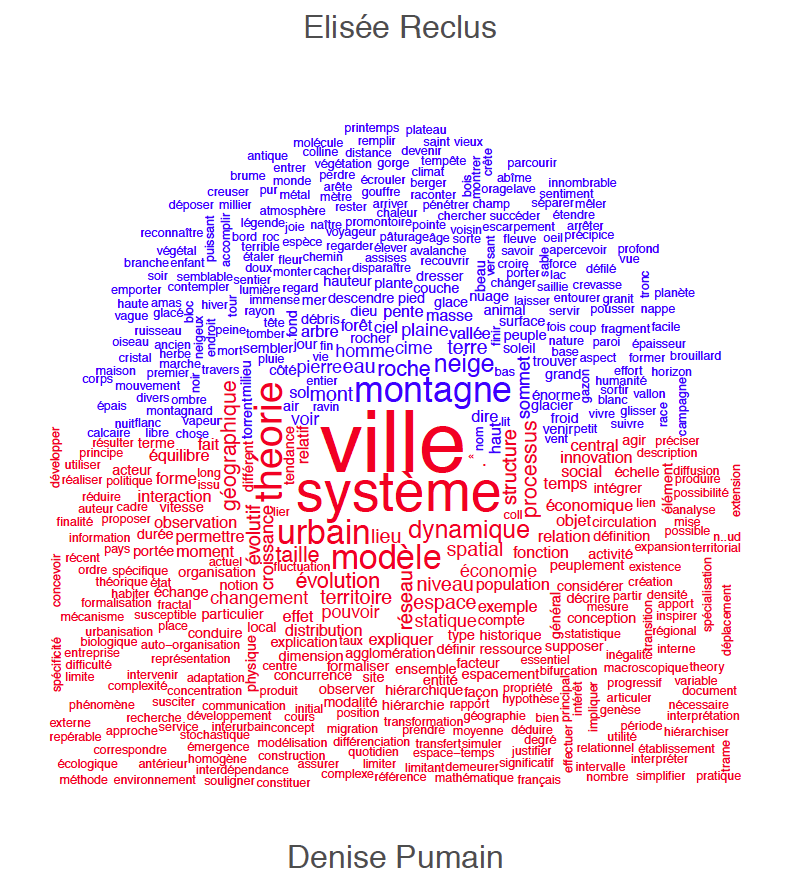
Que pouvez-vous dire à partir de cette image? Lequel des deux géographes fait preuve d’une plus grande diversité lexicale?
Examinez les relations entre les mots
La fonction kwic
Au-delà des fréquences de mots, il est intéressant d’apprendre dans quels contextes ils apparaissent. Par exemple, comment est employé le mot “croissance”? La commande suivante permet de voir où l’emploient nos deux géographes:
kwic(moncorpus,"territoire",window=3)Code language: JavaScript (javascript)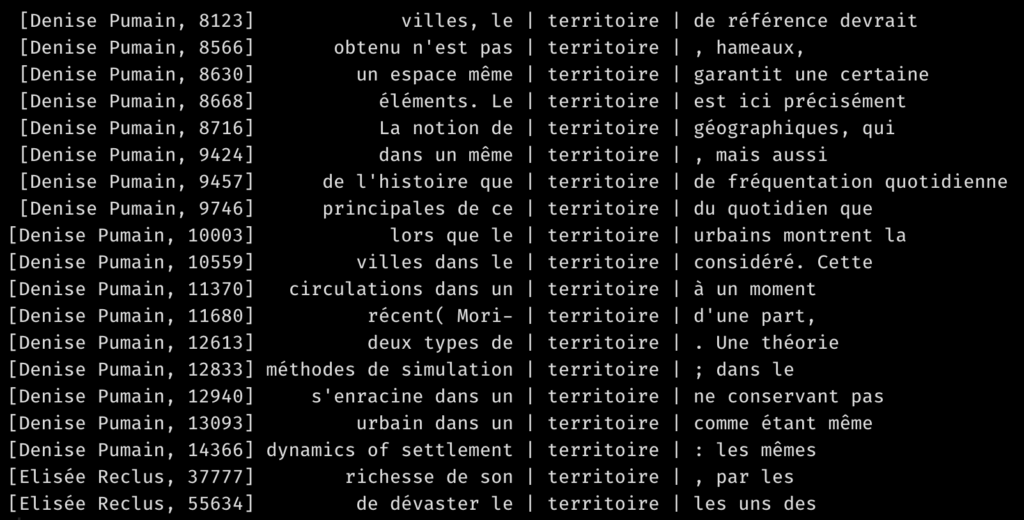
La fonction “feature coocurrence matrix“
Qu’en est-il plus généralement? Pour l’apprendre, vous pouvez utiliser la fonction “feature coocurrence matrix” (fcm). Cette dernière fonctionne ainsi:
fcm("un simple exemple pour un simple texte", context="window", window=1, tri=FALSE)Code language: JavaScript (javascript)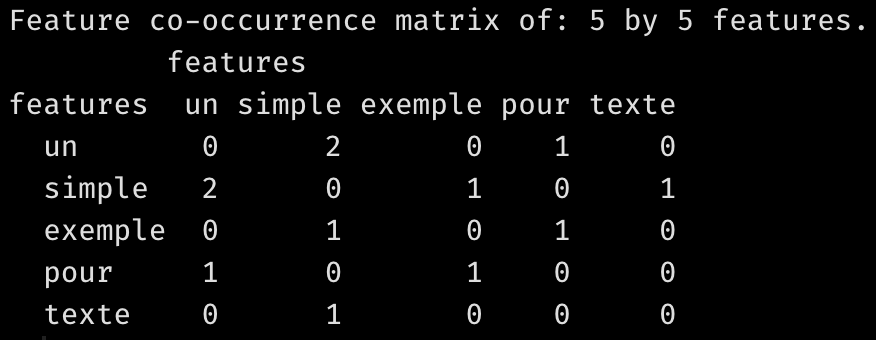
Comme vous le constatez, cette fonction produit une matrice carrée et symétrique de coocurrences de mots. Elle nous dit par exemple que les mots “exemple” et “pour” interviennent une fois côte à côte dans la phrase considérée. Ou que les mots “un” et “simple” interviennent deux foix côte à côte. Vous aurez constaté que nous avons donné plusieurs paramètres à la fonction fcm. Le paramètre window=1, par exemple, dit que nous la fonction compte les mots dans une fenêtre de 1 mot à gauche ou à droite de chaque mot considéré. Pour en apprendre davantage sur les parmètres de la fonction fcm(), consultez la documentation de Quanteda.
Vous pouvez appliquer la fonction fcm() à une phrase, à un texte ou à un corpus entier. Créons des matrices de cooccurrence pour nos deux textes de géographes:
fcmPumain <- fcm(mestexteslemmatises[[1]], context="window")
fcmReclus <- fcm(mestexteslemmatises[[2]], context="window")Code language: JavaScript (javascript)Visualiser les matrices de cooccurrence
Ces matrices de cooccurrence de mots dans des textes longs sont trop grandes pour être examinées sous forme de tableau. Mais nous pouvons les visualiser comme des réseaux (voir aussi: Visualiser des réseaux géographiques). Cela peut être fait à l’aide d’outils externes ou à l’aide d’outils internes de R et spécifiquement, de Quanteda, comme la fonction textplot_network(). Essayons:
textplot_network(fcmPumain)Comme vous le verrez, la console de R retourne une erreur:

Il faut réduire la taille de la matrice de cooccurrence de mots. Par exemple en ne gardant que les 50 mots les plus fréquents:
featPumain <- names(topfeatures(fcmPumain, 50))
fcmPumain_selected <- fcm_select(fcmPumain, pattern = featPumain, selection = "keep")
textplot_network(fcmPumain_selected)Code language: JavaScript (javascript)En exécutant les lignes ci-dessus, vous devriez obtenir le réseau de mots (lématisés) les plus fréquents dans le texte de Denise Pumain. Plus les liens entre eux sont épais, plus souvent ils interviennent à proches les uns des autres. On voit par exemple que Denise Pumain parle souvent de “système urbain” ou de “système dynamique”. Ou que les notions de “distribution” et de “taille” sont souvent évoquées conjointement. Que voyez-vous d’autre la visualisation ci-dessous?

Comparons enfin ce réseau à celui d’Élisée Reclus:
featReclus <- names(topfeatures(fcmReclus, 50))
fcmReclus_selected <- fcm_select(fcmReclus, pattern = featReclus, selection = "keep")
textplot_network(fcmReclus_selected)Code language: JavaScript (javascript)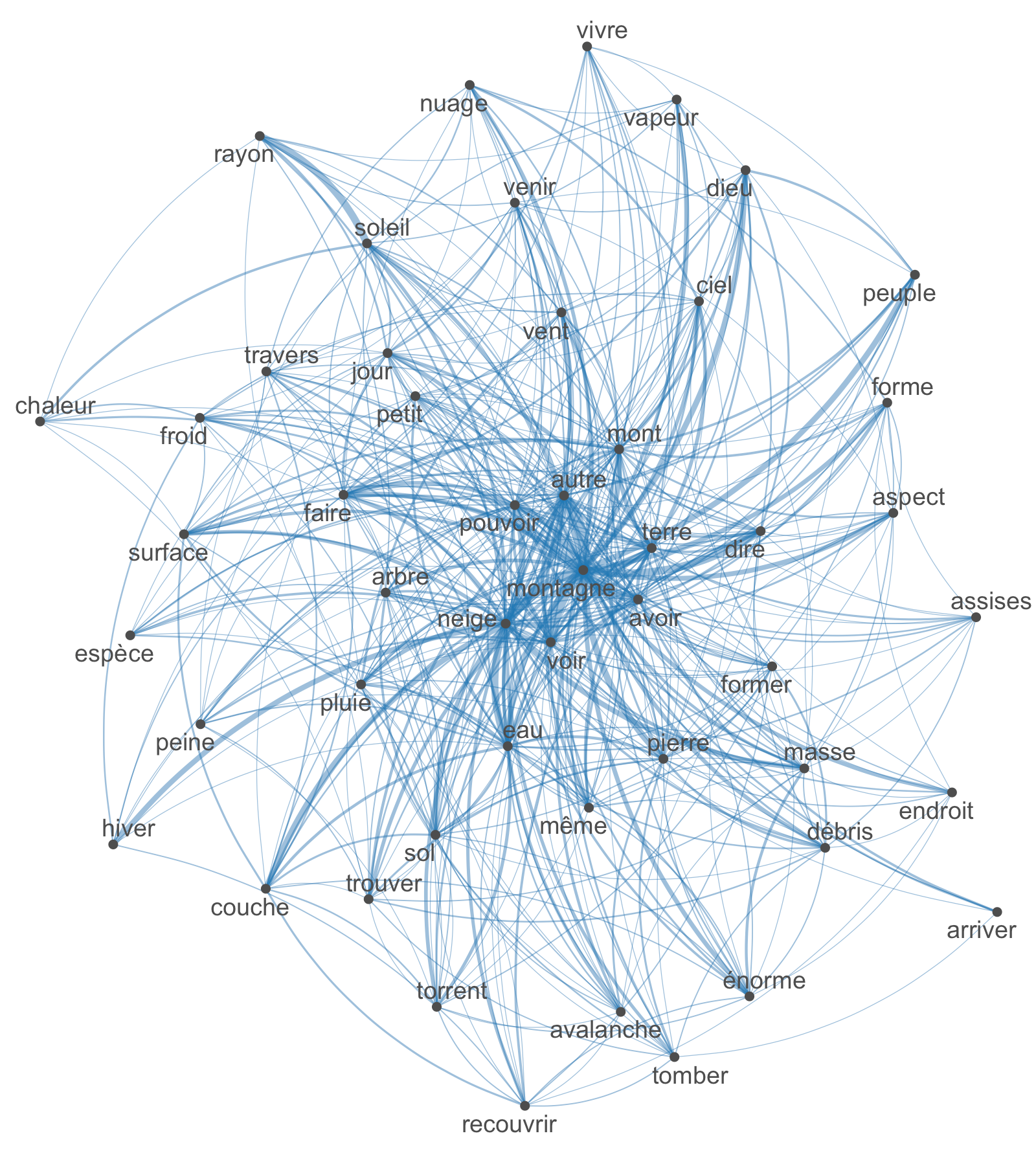
Aller plus loin
L’analyse linguistique quantitative ne se limite pas, bien sûr, à la création de nuages de mots et aux réseaux de cooccurrence. Vous pouvez, entre autres:
- Considérer le tokens de plusieurs mots (les n-grammes).
- Faire des découpages et des classifications thématiques automatiques (topic modeling).
- Détecter des opinions ou des sentiments exprimés dans les textes à l’aide de dictionnaires ou de procédures plus complexes.
Nous pouvons nous pencher ces autres aspects en fonction de vos besoins et intérêts.

")

merci pour cette présentation très claire !