La modélisation par régression de l’occupation des sols (Land Use Regression, LUR) cherche à prédire les valeurs locales d’une variable à partir de caractéristiques environnementales mesurées dans des zones tampons (buffers) autour du lieu de prédiction. La LUR permet de créer des cartes de chaleur (heatmaps) à haute résolution des valeurs de la variable prédite. C’est une méthode de modélisation spatiale souvent utilisée pour étudier les phénomènes comme la concentration de pollution atmosphérique, l’exposition aux pathogènes en santé publique, le bruit environnemental, les champs électromagnétiques, etc.
Hypothèses et fondements mathématiques
La LUR repose ainsi, par exemple, sur l’hypothèse que les conditions d’occupation des sols environnantes peuvent servir à prédire la variation des concentrations de pollution atmosphérique. Le processus peut être divisé en cinq étapes principales, à savoir :
- Collecte des observations de pollution atmosphérique.
- Identification des conditions d’utilisation des sols environnantes dans des zones tampons autour des observations de pollution atmosphérique.
- Ajustement d’un modèle statistique pour expliquer la variation des observations de pollution atmosphérique en fonction des conditions d’utilisation des sols. Traditionnellement, il s’agit d’un modèle de régression linéaire.
- Validation croisée incluant un regroupement spatial et/ou temporel.
- Production d’une carte de pollution atmosphérique.
Le modèle statistique qui définit une LUR est en règle un modèle de régression linéaire classique:
- y : La variable dépendante (ex.: la concentration annuelle moyenne de NO2 à un point précis).
- β0 : L’ordonnée à l’origine (le “background” ou niveau de pollution de fond constant).
- βi : Les coefficients de régression pour chaque prédicteur i. Ils indiquent l’intensité de l’influence de chaque variable sur la pollution locale.
- Xi : Les variables explicatives (prédicteurs) calculées dans des zones tampons (buffers). Par exemple :
- X1 : Densité du trafic dans un rayon de 100m.
- X2 : Surface industrielle dans un rayon de 500m.
- X3 : Altitude du point.
- ϵ : L’erreur résiduelle (la part de variabilité non expliquée par le modèle).
Mais d’autres techniques de régression interviennent parfois. Par exemple, une régression semi-logarithmique pour stabiliser la variance et pour éviter de prédire des valeurs négatives, dépourvues de sens quand on parle de concentration de molécules:
Exercice de traitement avec R
Dans cet exercice, nous allons prédire la température à partir de l’altitude et de l’usage du sol. Cet exercice présuppose que vous ayez déjà maîtrisé les bases de la cartographie avec R.
Pour commencer, chargez les données de l’exercice ici. Tout le reste du traitement se fera uniquement dans R.
Modules nécessaires au traitement
library(sf) # Gestion des géodonnées vecteur
library(ggplot2)
library(magrittr)
library(ggnewscale) # Indispensable pour avoir deux échelles 'fill'
library(openxlsx)
library(dplyr)
library(purrr)
library(corrplot)
library(terra) # Gestion des géodonnées rasterCode language: R (r)Importation et vérification des données
Dans le code ci-dessous, ajustez la valeur de datapath de manière à pointer vers le dossier de vos géodonnées. Nous importons d’abord les données de l’usage du sol de l’OFS (arealstatistik2025_neuch.gpkg) et nous leur associons les altitudes contenues dans un modèle numérique du terrain raster (dem_neuch.tif). Attention: les agrégations ne marcheront que si toutes vos géodonnées sont dans la même projection.
Nous récupérons aussi les noms des types d’usages du sol du fichier Excel fourni par l’OFS (arealstatistik_2056_metadata.xlsx, p. ex. 100 = Aires de bâtiments, 120 = Surfaces de transport, etc.) Ceci nous sera utile plus tard.
Notez l’usage de la fonction terra::extract(dem, terra::vect(usages_sol)) et, à l’intérieur de celle-ci, de terra::vect(usages_sol), qui permet de caler les données d’altitude (dem) sur les coordonnées de la couche de points (usages_sol).
# le chemin vers votre dossier de données (ici dossier "data" à partir du dossier contenant de votre script .Rmd actuel)
datapath <- file.path(dirname(rstudioapi::getActiveDocumentContext()$path),"data")
# variante:
# datapath <- chemin/complet/vers/votre/dossier/data
# usage du sol et ses métadonnées
usages_sol <- st_read(file.path(datapath,"arealstatistik2025_neuch.gpkg"))
usages_sol_metadata <- read.xlsx(file.path(datapath,"arealstatistik_2056_metadata.xlsx"),sheet="Codes LU_10")
usages_sol <- usages_sol %>%
left_join(usages_sol_metadata, by = c("LU_10" = "CODE"))
# modèle d'altitude
dem <- rast(file.path(datapath,"dem_neuch.tif"))
altitude_values <- terra::extract(dem, terra::vect(usages_sol)) # terra::vect(usages_sol) permet de caler les données sur les coordonnées de la couche de points usages_sol
usages_sol$altitude <- altitude_values$dem_neuch / 10 # division par 10 pour avoir les mètres
ggplot() +
geom_sf(
data = usages_sol,
aes(
fill = altitude,
color = altitude
),
shape = 15, # carré
size = 0.5
)Code language: R (r)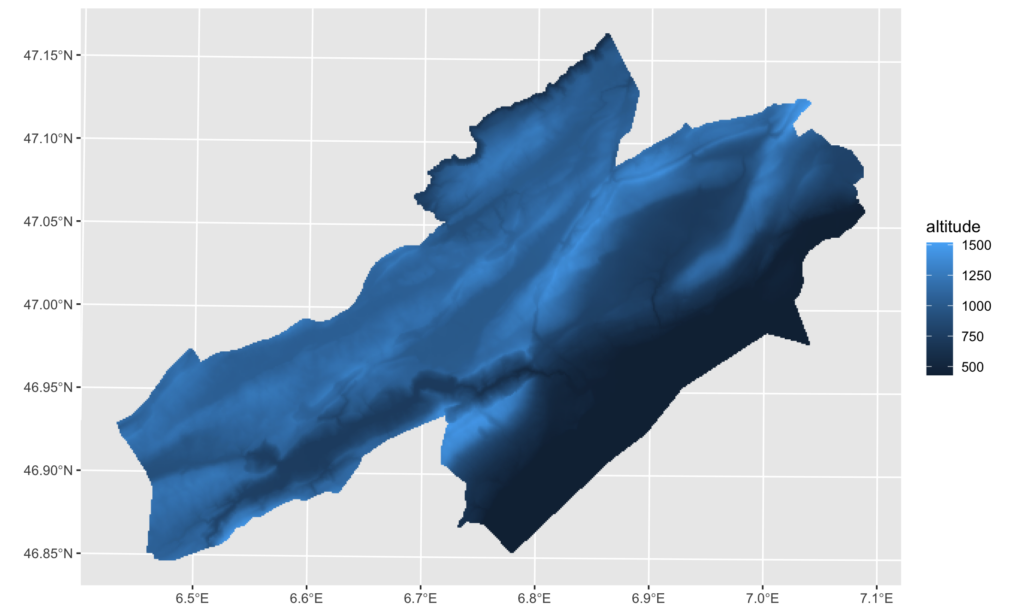
Ajoutons les données de stations de mesure de température (les données du présent exemple sont fictives) et vérifions les données d’usage du sol.
# stations de mesure
mesures <- st_read(file.path(datapath,"mesures.gpkg"))
ggplot() +
geom_sf(
data = usages_sol,
aes(
fill = LABEL_FR,
color = LABEL_FR
),
shape = 15, # carré
size = 0.1
) +
new_scale_fill() + # nécessaire pour avoir une nouvelle échelle de remplissage
geom_sf(
data = mesures,
aes(fill = temp_moyenne_nuit),
shape = 21, # cercle avec remplissage et contour
color = "white", # Contour
size = 3,
stroke = 0.5
) +
theme(
legend.box = "horizontal", # Aligne les différentes légendes horizontalement
legend.position = "right",
legend.box.just = "top" # ajuste l'alignement vertical des légendes entre elles
)Code language: R (r)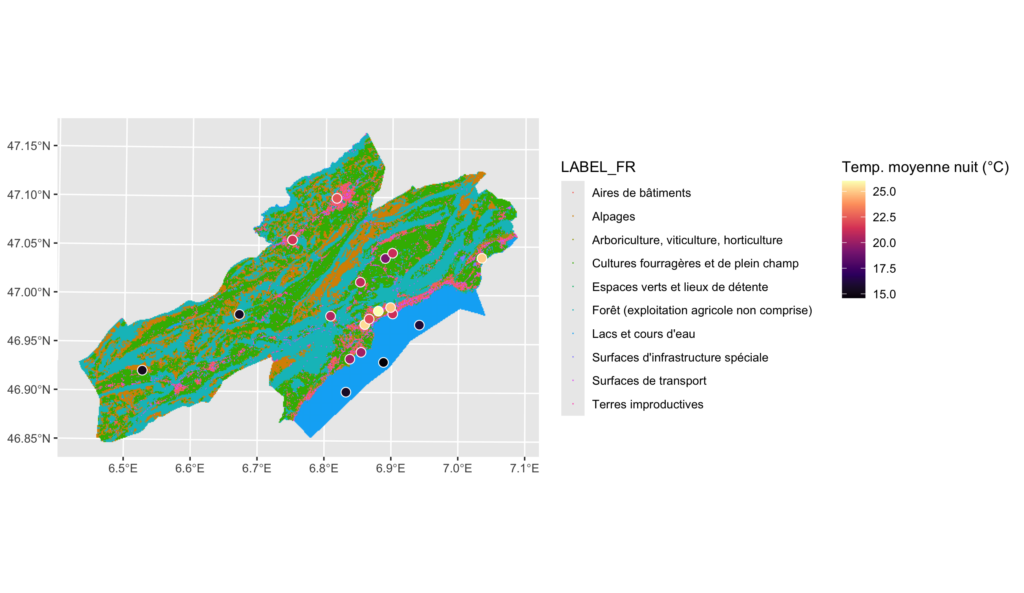
Calcul de valeurs par buffer autour de chaque station de mesure
Nous mesurons notamment la proportion de chaque usage du sol, ainsi que l’altitude moyenne, sur l’ensemble de terrain à l’intérieur de chaque buffer. Ceci permettra d’associer ces valeurs à la température mesurée.
mesures$station_id <- 1:nrow(mesures) # création d'un ID unique pour les stations de mesure, afin de pouvoir faire, plus tard, des jointures statistiques
mesures_buffer <- st_buffer(mesures, dist = 300) # Création d'un buffer autour des stations
# Jointure spatiale : on identifie quels points d'usage du territoire tombent dans quel buffer de station de mesure
points_dans_buffers <- st_join(usages_sol, mesures_buffer, left = FALSE)
# Calcul des proportions par buffer
stats_buffer <- points_dans_buffers %>%
st_drop_geometry() %>% # On passe en tableau simple pour la vitesse
group_by(station_id, LU_10) %>%
summarise(nb_points = n(), .groups = "drop_last") %>%
mutate(proportion = nb_points / sum(nb_points)) # Proportion par rapport au total du buffer
stats_large <- reshape(
as.data.frame(stats_buffer[c("station_id", "LU_10", "proportion")]),
idvar = "station_id", # La colonne qui identifie les stations
timevar = "LU_10", # La colonne dont les valeurs deviendront des noms de colonnes
direction = "wide" # On passe du format long au format large
)
stats_large[is.na(stats_large)] <- 0 # Remplacer les NA par 0 pour toutes les colonnes de proportions
colnames(stats_large) <- gsub("proportion\\.", "prop_LU", colnames(stats_large))
stats_buffer_altitude <- points_dans_buffers %>%
st_drop_geometry() %>% # On passe en tableau simple pour la vitesse
group_by(station_id) %>%
summarise(altitude = mean(altitude))
mesures_finales <- list(mesures,stats_large,stats_buffer_altitude) %>%
reduce(full_join, by = "station_id")Code language: R (r)Identification de variables utiles pour la prédiction
À part l’altitude, que nous sommes sûrs de vouloir garder pour la prédiction de température, nous avons les dix types d’usage du sol suivants, dont nous connaissons désormais la proportion dans chaque buffer.
| CODE | LABEL_DE | LABEL_FR |
| 100 | Gebäudeareal | Aires de bâtiments |
| 120 | Verkehrsflächen | Surfaces de transport |
| 140 | Besondere Siedlungsflächen | Surfaces d’infrastructure spéciale |
| 160 | Erholungs- und Grünanlagen | Espaces verts et lieux de détente |
| 200 | Obstbau, Rebbau, Gartenbau | Arboriculture, viticulture, horticulture |
| 220 | Acker- und Futterbau | Cultures fourragères et de plein champ |
| 240 | Alpwirtschaft | Alpages |
| 300 | Wald (ohne landwirtschaftliche Nutzung) | Forêt (exploitation agricole non comprise) |
| 400 | Seen und Flüsse | Lacs et cours d’eau |
| 420 | Unproduktives Land | Terres improductives |
Avec une vingtaine de stations de mesure seulement, il n’est pas judicieux de garder toutes ces variables. Avec si peu de points de mesure empirique de la variable dépendante y (à prédire pour le reste du territoire), garder les dix variables prédictives mènerait le modèle à créer des coefficients “monstrueux” pour réussir à passer exactement par nos points de mesure, sans aucune logique physique. En statistique, d’ailleurs, quand on travaille sur des proportions, dont l’addition fait 100%, on doit exclure au moins une variable (celle-ci devient la “référence” incluse dans l’ordonnée d’origine β0 du modèle). Bref, nous n’allons pas garder toutes les variables. Pour choisir celles à exclure, regardons d’abord les histogrammes de leurs valeurs:
props_uniquement <- mesures_finales[, grep("prop_LU|altitude", names(mesures_finales))] %>% st_drop_geometry
par(mfrow = c(3, 4)); sapply(names(props_uniquement), function(x) hist(props_uniquement[[x]], main = x, xlab = "Prop", col = "steelblue"))Code language: JavaScript (javascript)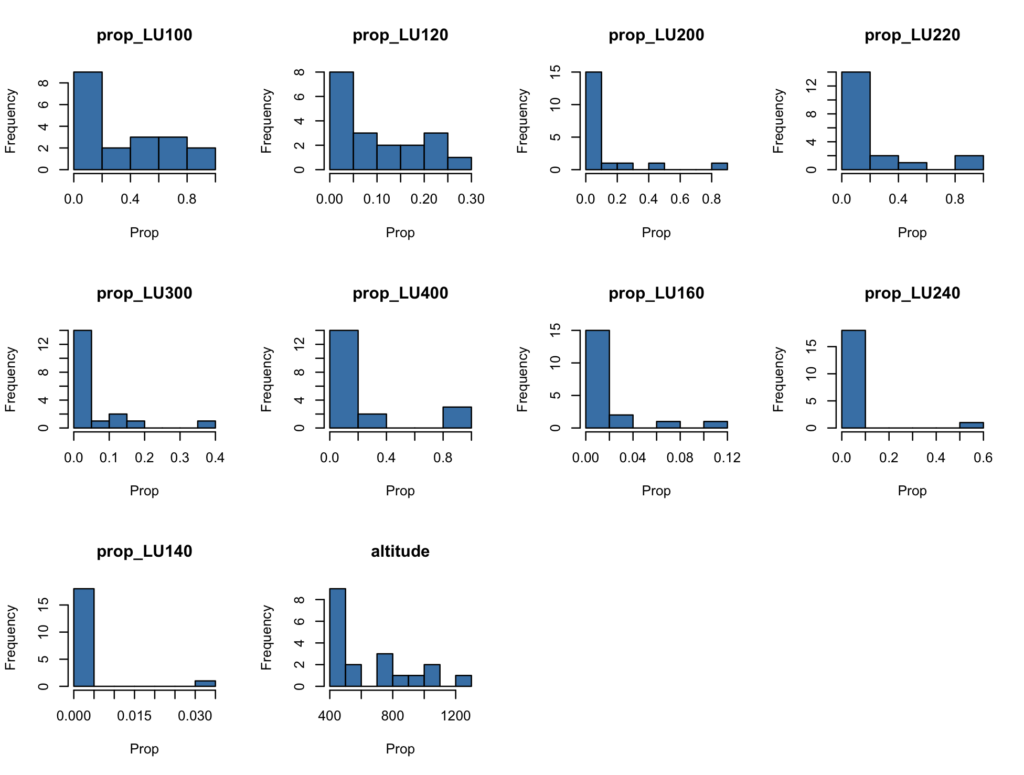
On voit par exemple que la proportion de surfaces d’infrastructure spéciale (LU140) ne dépasse jamais 3%. La proportion des alpages (LU240), quant à elle, dépasse bien les 50% une fois, mais reste inférieure à 10% dans l’écrasante majorité des stations de mesure, ce qui en fait une variable prédictrive peu utile.
Une analyse des corrélations permet aussi de vérifier si certaines variables ne redoublent pas juste l’information déjà portée par d’autres
cor(props_uniquement, use = "complete.obs") %>% corrplotCode language: R (r)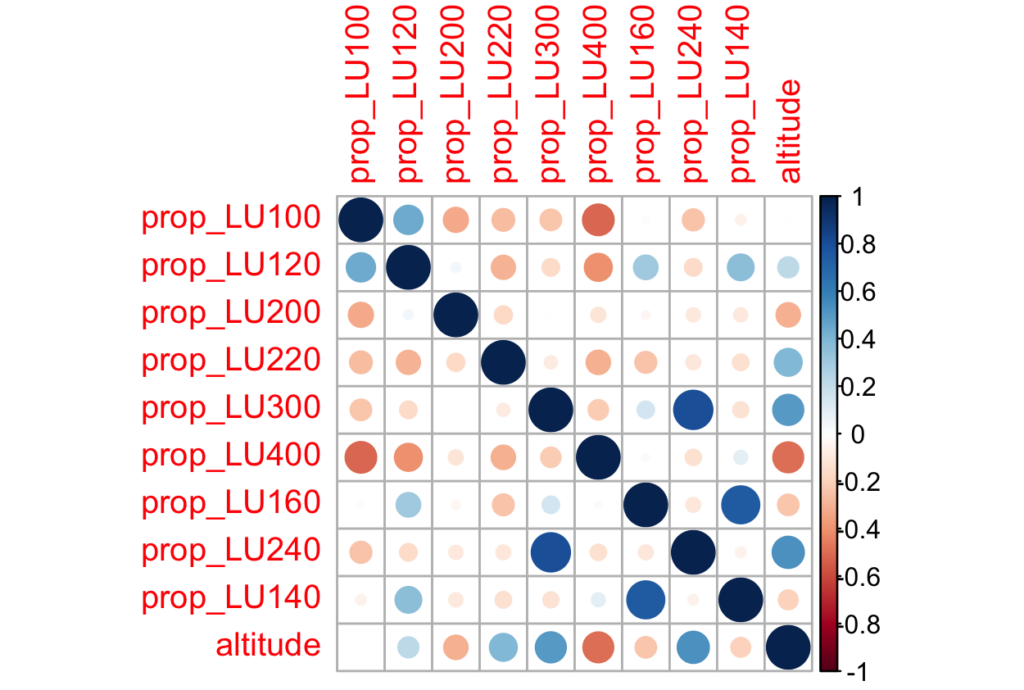
On voit, par exemple, que le proportions de surfaces d’infrastructure spéciale (LU140) corrèlent presque parfaitement avec les espaces verts et de détente (LU160); une fois de plus, on peut se passer de la variable prop_LU140. La proportion de lacs (LU400) est quant à elle très fortement négativement corrélée avec les zones bâties (LU100) et l’altitude; on peut aussi y renoncer. Enfin, les proportions d’alpages (LU240) et de forêts (LU300) sont trop corrélées pour garder les deux; n’en gardons donc qu’une.
Voici un modèle possible, en gardant seulement les variables les plus utiles:
modele_lur <- lm(temp_moyenne_nuit ~ prop_LU100 + prop_LU200 + prop_LU300 + altitude, data = mesures_finales)
summary(modele_lur)Code language: HTML, XML (xml)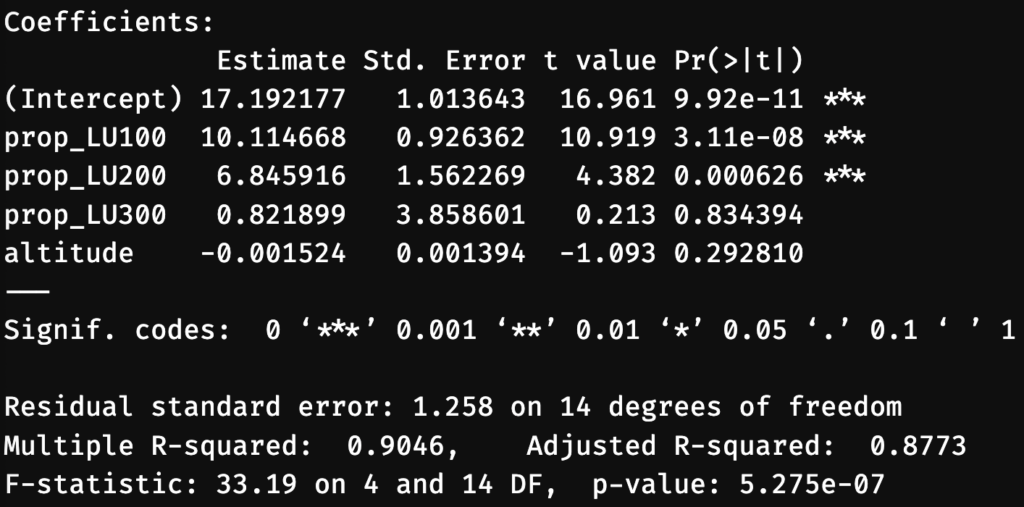
La colonne Estimate nous donne les coefficients β du modèle de prédiction. La colonne Pr(>|t|)donne le résultat du test de significativité du coefficient, autrement dit, la probabilité que ce dernier relève simplement d’un bruit statistique. On voit que celle-ci est très élevée pour la proportion de forêts (prop_LU300). Nous allons donc enlever cette variable du modèle:
modele_lur <- lm(temp_moyenne_nuit ~ prop_LU100 + prop_LU200 + altitude, data = mesures_finales)Code language: HTML, XML (xml)Prédiction des températures par le modèle LUR
Pour appliquer le modèle, on crée des buffers autour de tous les points de la grille d’usage du sol, en utilisant la même distance (dist) que pour le modèle. On calcule les proportions et les altitudes moyennes pour chaque point de la grille C’est la même logique que précédemment:
grille_pred_buffer <- st_buffer(usages_sol, dist = 300)
grille_pred_buffer$grid_id <- 1:nrow(grille_pred_buffer)
# Proportions pour chaque point de la grille
inter <- st_join(usages_sol, grille_pred_buffer, left = FALSE)
stats_pred <- inter %>%
st_drop_geometry() %>%
group_by(grid_id, LU_10.x) %>%
summarise(n = n(), .groups = "drop_last") %>%
mutate(prop = n / sum(n)) %>%
ungroup()
stats_pred_large <- reshape(
as.data.frame(stats_pred[c("grid_id", "LU_10.x", "prop")]),
idvar = "grid_id", timevar = "LU_10.x", direction = "wide"
)
stats_pred_large[is.na(stats_pred_large)] <- 0 # Remplacer les NA par 0 pour toutes les colonnes de proportions
colnames(stats_pred_large) <- gsub("prop\\.", "prop_LU", colnames(stats_pred_large))
stats_pred_altitude <- grille_pred_buffer %>%
st_drop_geometry() %>% # On passe en tableau simple pour la vitesse
group_by(grid_id) %>%
summarise(altitude = mean(altitude))
stats_pred_finales <- list(stats_pred_large,stats_pred_altitude) %>%
reduce(full_join, by = "grid_id")Code language: R (r)Application du modèle (La Prédiction)
La fonction predict() va chercher dans la data.frame stats_pred_large les colonnes dont elle a besoin. Elle ignorera simplement les colonnes que nous n’avons pas pris en compte dans le modèle (pour rappel, nous prédisons temp_moyenne_nuit à l’aide des valeurs de prop_LU100, prop_LU200, prop_LU300 et altitude).
usages_sol$temp_predite <- predict(modele_lur, newdata = stats_pred_finales)
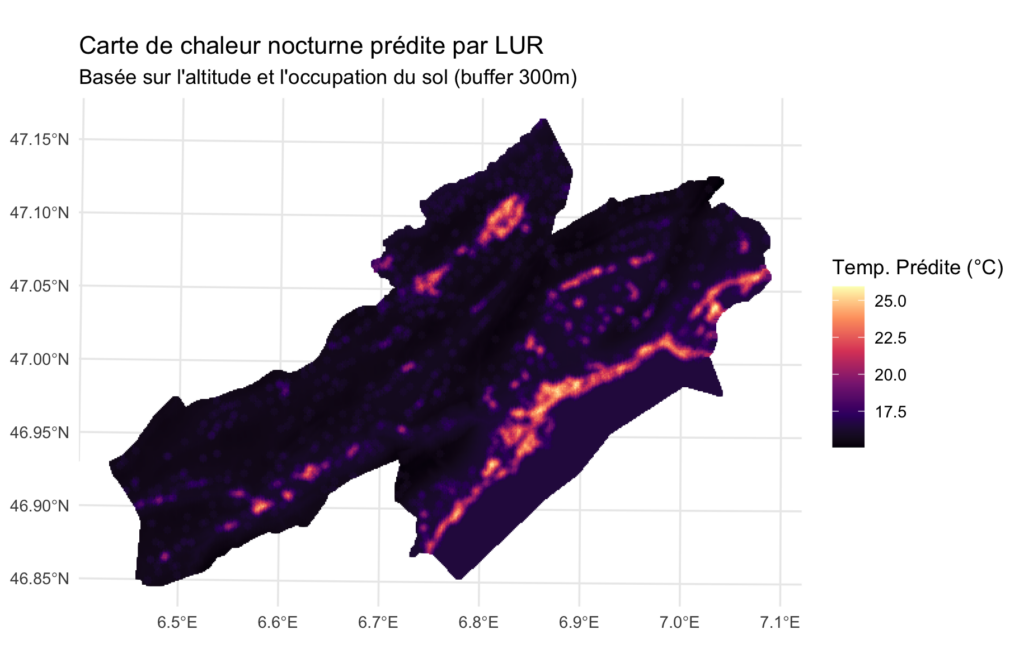
ggplot(usages_sol) +
geom_sf(aes(color = temp_predite), shape = 15, size = 1) +
scale_color_viridis_c(option = "magma", name = "Temp. Prédite (°C)") +
theme_minimal() +
labs(title = "Carte de chaleur nocturne prédite par LUR",
subtitle = "Basée sur l'altitude et l'occupation du sol (buffer 300m)")Code language: HTML, XML (xml)