DeepZoom allows webmasters to display high resolution images in an online viewer. Among its users:
- The British Library
- The World Digital Library (WDL)
- Polona, the Polish Digital National Library
- BALaT, Belgian Art Links and Tools
- and many others
DeepZoom mostly discourages downlading the original high resolution images to your local drive. This is how to get these images nevertheless with the help of R.
Examining a web page containing Deep Zoom
First, let us have a look at an example of a webpage using DeepZoom. For the rest of this tutorial, it is better to use the Chrome navigator.

The DeepZoom interface displays 4 images from which you can select and into which you can… zoom. You can also see the interface in full-screen by clicking one of the buttons in the bottom right corner, but non of these allow you to download the original image.
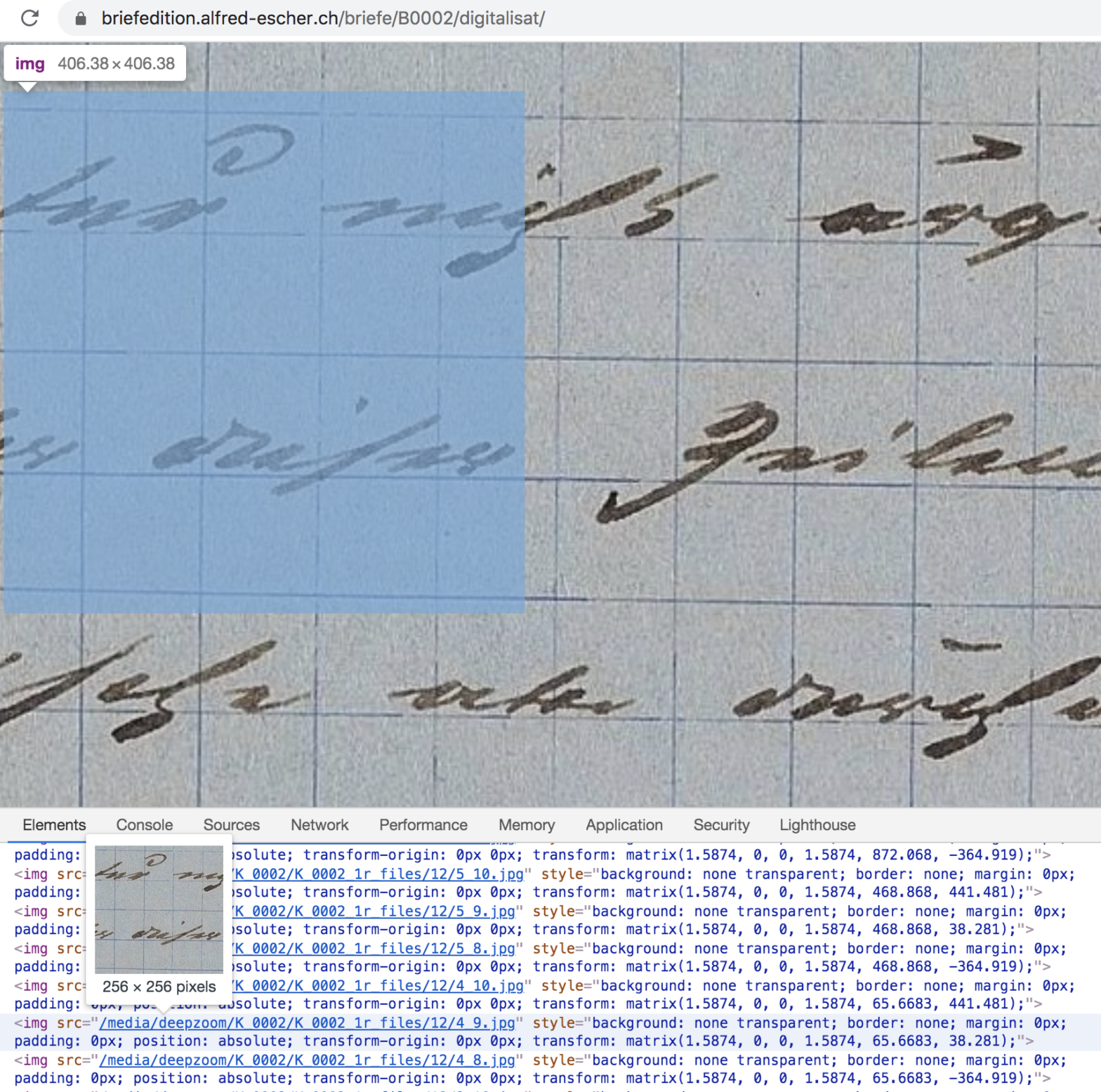
Go into full-screen mode, zoom into the image to the maximum and inspect what you see by clicking F12 or by using the inspector in the contextual menu:

The image tiles matrix
As you’ll see, the Deep Zoom interface does not actually show a single image but a whole matrix of image tiles. To recompose each original image, you will have to download all the individual tiles and combine them into a large image. This is what the R code below allows you to do.
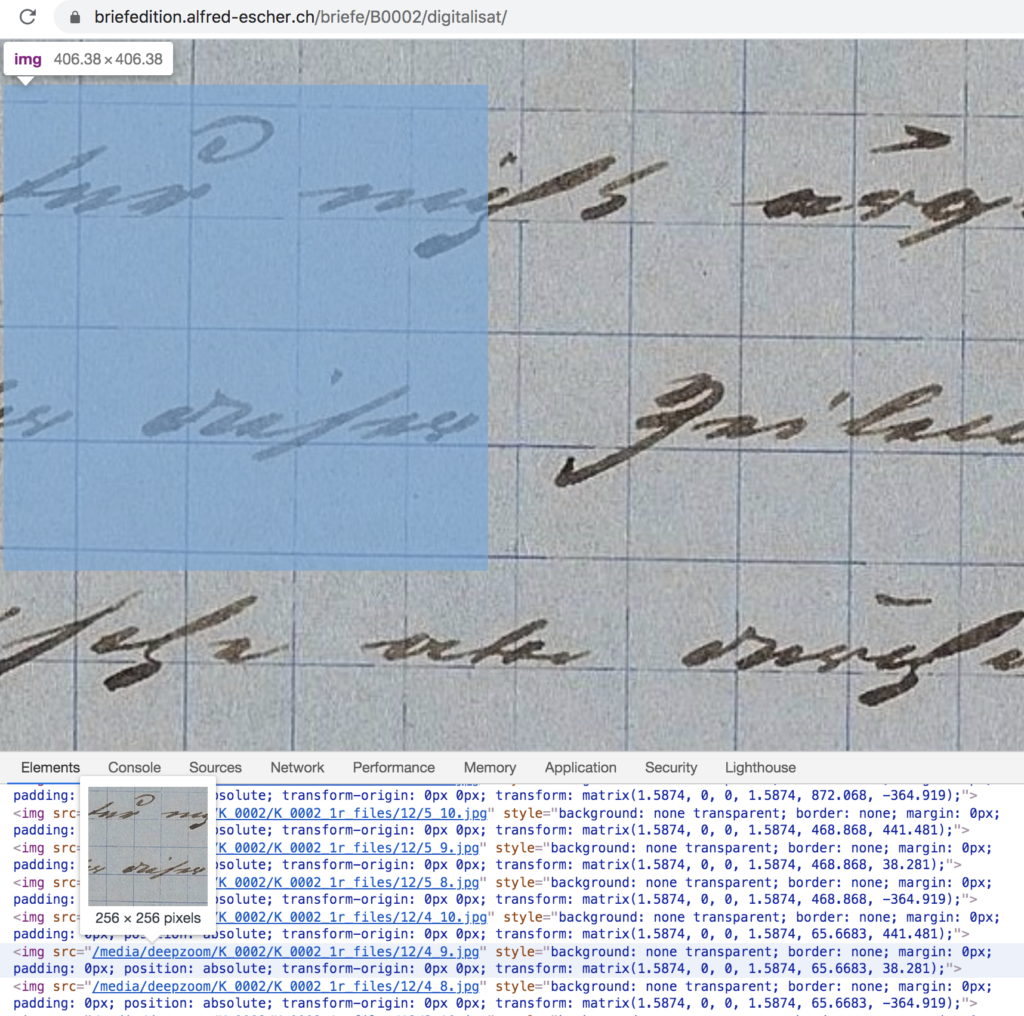
Before trying to use the code, you need to examine several things.
First, the relative URLs of some individual image tiles:
- /media/deepzoom/K_0002/K_0002_1r_files/12/4_9.jpg
- /media/deepzoom/K_0002/K_0002_1r_files/12/4_8.jpg
- etc.
Note that each URL contais a subfolder /12/. This is the maximum resolution level. In my R code, you can use this as a parameter of the maxres variable. In a different site, this maximum value will be different.
Also note the numbereing of the jpegs: In DeepZoom, this numbering always starts with 0_0.jpg up to i_j.jpeg, where i and j stand for the “coordinates” of the image tile in the bottom right corner. Just scroll to that image, while remaining at a maximum zoom level. In the R code, set maxi and maxi reasonably above this maximum value, since other images on the site could be larger.
A look at the source code
Than leave the fullscreen mode and have a look at the static source code (i.e. the source code of the page before any javascript has altered it). Search for “deepZoom”:

Verify that the <div> element containg the Deep Zoom resources, in this examples, four <img> elements. The source (src) of these elements points to a low-res image used for the thumbnails (zoom level 8 in this cas), but gives you an essential hint regarding the base folder containing the deep zoom tiles for each image. For instance, from the first image, you can deduce that there is a folder named /media/deepzoom/K_0002/K_0002_1r_files/. From previous analysis , you know that the highest resolution is 12, so you want to download all jpegs from the folder /media/deepzoom/K_0002/K_0002_1r_files/12/. My R code does this for you, for all images, and their high-res image tiles, found in the <div id="deepZoomSeadragon">
On other sites, the id might be different. If it is, you’ll need to adpapt the xpath value in the R code line reading:
jpegurls <- html_nodes(deepzoompage,xpath="//div[@id='deepZoomSeadragon']//img")Code language: HTML, XML (xml)The R code
For the rest, the code should be self-explaing. I use the neat magick R package to recompose the whole image from the tiles. This in two embedded for-loops. The recomposing magic happens in the line
thisimageline <- image_append(c(thisimageline, newimage), stack=TRUE)Code language: HTML, XML (xml)Where stack=TRUE means that you append image tiles vertically. This gives you a column of images of 1-image width. In the encompassing loop, you append columns horizonataly until you have the full width of the original image:
thisimage <- image_append(c(thisimage, thisimageline))Here is the full code:
# Load required libraries ----
library(rvest)
library(magick)
library(magrittr)
library(stringr)
library(data.table)
# Define the url of the page containing the images embedded in DeepZoom ----
deepzoompageurl <- "https://briefedition.alfred-escher.ch/briefe/B0002/digitalisat/"
# Define the maximum resolution observed on the page, as well as maximum i and j dimensions ----
maxres <- 12
maxi <- 15
maxj <- 20
# Define your output location
imageoutfolder <- "/Users/ourednik/Documents/BAR/Escher/imageshighres/"
# Find the individual images on a DeepZoom page
flag <- TRUE
deepzoompage <- tryCatch(
read_html(deepzoompageurl),
error = function (e) {flag <<- FALSE}
)
if (flag) {
jpegurls <- html_nodes(deepzoompage,xpath="//div[@id='deepZoomSeadragon']//img") %>% html_attr("src")
jpegcount <- length(jpegurls)
images <- data.table(
imgnum=str_pad(1:jpegcount,3,pad="0"),
jpegurl=jpegurls
)
} else { print("images not found")}
# Have a look at images ----
images
# Extract the DeepZoom folder and make a fully qualified url
# Example of an extracted url /media/deepzoom/K_0002/K_0002_1r_files/8/0_0.jpg
sitebaseurl <- str_extract(deepzoompageurl,"https:\\/\\/[^\\/]*") # Since the URL is relative we get the site's root to be able to prepend it
images[,deepzoommaxresfolder:=str_replace(jpegurl,"8/0_0.jpg",paste0(maxres,"/")) %>% paste0(sitebaseurl,.) ]
# Read all individual image tiles into memory and recompose the original image
for (b in 1:nrow(images)) {
dzfolder <- images[b]$deepzoommaxresfolder
outfilename <- paste0(images[b]$imgnum,".jpg")
thisimage <- NULL
for (i in 0:15) {
thisimageline <- NULL
for (j in 0:20) {
flag <- TRUE
tryCatch(
newimage <- image_read(paste0(dzfolder,i,"_",j,".jpg")),
error = function (e) {flag <<- FALSE}
)
if (!flag) break
if (j == 0) {thisimageline <- newimage}
else {thisimageline <- image_append(c(thisimageline, newimage), stack=TRUE)}
}
if (is.null(thisimageline)) break
if (i == 0) {thisimage <- thisimageline}
else {thisimage <- image_append(c(thisimage, thisimageline)) }
}
if (!is.null(thisimage)) {image_write(thisimage,file.path(imageoutfolder,outfilename))}
else (warning(paste0("The deepzoom folder ", dzfolder, " doesn't seem to exist\n")))
}Code language: PHP (php)That’s it. If you want to scrape all high-res images of a site, you’ll just need a list of all pages of that site containing a DeepZoom interface. For those of you used to scraping, this should be an easy task.