
After achieving an optimized string detection algorithm in R for 1 milion phrases using a 200k large dictionary, I wondered if I can get better results in Julia. My first attempt at this was a catastrophe. Within 24 hours, the Julia community helped me to learn some basics of Julia code optimization and proposed a blazing fast translation of my R code.
Preliminaries: Multithreading and Basic Setup
Even without multithreading, Julia turned out faster than the multithreaded version of my R code. But multithreaded Julia gets a tremendous speed boost. To run it from the command line, you need to start Julia with julia -p n where n is the number of threads. But you are better off using VSCode; it has a nice Julia Language Support extension, that allows you, among other things, to set the number of threads in the GUI:
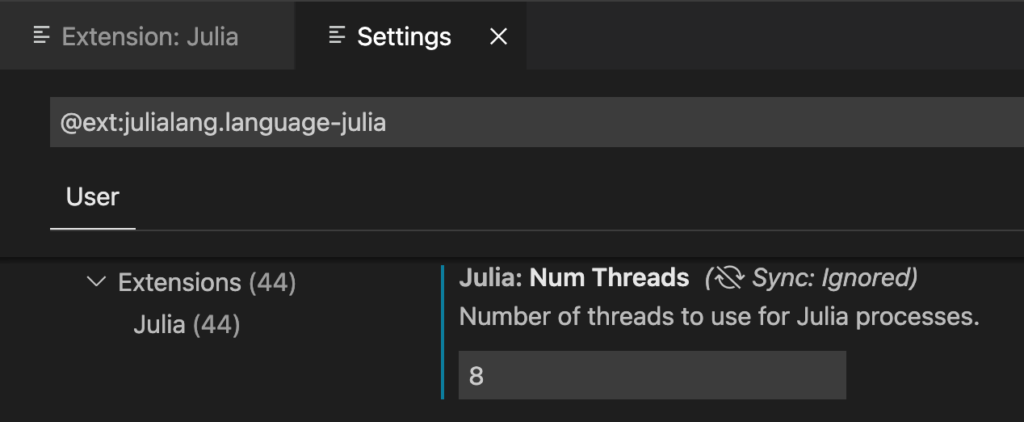
Also in VSCode, if you haven’t yet installed the Code Runner extension, do so. It will allow you tu run Julia code chunks with Alt-Enter, like you would run RMarkdown chunks in RStudio. A Julia code chunk is marked with ##.
A First Attempt
Don’t bother running this absolutely non-optimized version, the last chunk takes ages:
## Imports
import Pkg; Pkg.add("DataFrames")
using Random, DataFrames, StatsBase
## Preparing random text sample and dictionary
mseq = 1:100000
reference = String[]
textdata = DataFrame(
id = mseq,
textlong = "",
occurs = 0
)
Threads.@threads for i in mseq
push!(reference,randstring('A':'Z', 5))
textdata[i,"textlong"] = join([randstring('A':'Z', 5) for i in 1:rand(1:10)]," ")
end
reference = unique(reference)
reference = reference[1:20000]
## Running the detection
### for each reference entry generate a bytestring vector of length = nrows of textdata dataframe, then sum vectors
textdata.occurs = [occursin.(x,textdata.textlong) for x = reference] |> sum
result = filter(row -> row.occurs > 0 ,textdata)Code language: PHP (php)Grasping some Notions of Julia Code Optimization
A Julia community member quickly pointed me to a well documented page on code optimization. Not everything seemed easy to implement at first sight, but my three takaways are:
- Enclose all process-critical code parts in functions
- Declare variable types, e.g.:
occurrences = Vector{BitVector}(undef,200000)instead ofoccurrences = [].function detectwordinphrase(words::Vector{String},phrases::Vector{String})instead offunction detectwordinphrase(words,phrases)
- Avoid declaring globals, because globals in Julia are type-mutable, as are columns in data.frames; in other words: types don’t stick on globals and this slows down code compilation.
I must admit the last piece of advice was very frustrating to me. How can you run code dealing with data without declaring at least some globals? Thus, my second version was this, running better: close to 38 seconds to detect 20k words in 100k phrases with 8 threads. Still nowhere near the performance of my R code though, and a terrible memory use of over 250 GB:
## Preparing random text sample and dictionary
### This part only takes less than a second
using Random
textdata_ids = 1:100000
textdata_textlong = String[] ### Types should be declared for performance
textdata_occurs = Int[]
reference = String[]
using Random
for i in textdata_ids
push!(reference,randstring('A':'Z', 5))
push!(textdata_textlong,join([randstring('A':'Z', 5) for j in 1:rand(1:10)]," "))
end
reference = unique(reference)
reference = reference[1:2000]
## Define the detection function and run it
function detectwordinphrase(words::Vector{String},phrases::Vector{String})
# occurrences = [occursin.(x,phrases) for x::String = words]
occurrences = Vector{BitVector}(undef,length(words))
Threads.@threads for i = 1:size(words,1) # This loop takes all of the time
occurrences[i] = occursin.(words[i],phrases)
end
return sum(occurrences) # This takes no time at all
end;
@time textdata_occurs = detectwordinphrase(reference,textdata_textlong)
# Single threaded:
# 10k phrases 2k words : 0.929850 seconds (40.01 M allocations: 2.544 GiB, 7.86% gc time)
# 100k phrases 2k words : 11.996917 seconds (400.01 M allocations: 25.363 GiB, 7.66% gc time)
# 100k phrases 20k words : 112.146993 seconds (4.00 G allocations: 253.637 GiB, 11.36% gc time)
# Multithreaded 4 threads
# 100k phrases 2k words : 5.061899 seconds (400.01 M allocations: 25.363 GiB, 37.20% gc time)
# 100k phrases 20k words : 50.659987 seconds (4.00 G allocations: 253.655 GiB, 35.53% gc time)
# Multithreaded 8 Threads
# 100k phrases 20k words : 37.712681 seconds (4.00 G allocations: 253.655 GiB, 51.64% gc time, 0.16% compilation time)Code language: Julia (julia)The Community Solution
Than came along Julia comunity member lawless-m:
using Random
function fill(n)
## Preparing random text sample and dictionary
searchterms = Vector{String}(undef, n)
textdata = Vector{Vector{String}}(undef, n)
Threads.@threads for i in 1:n
searchterms[i] = randstring('A':'Z', 5)
textdata[i] = [randstring('A':'Z', 5) for _ in 1:rand(1:10)]
end
textdata, unique(searchterms)
end
function processT(textdata, searchset)
n = size(textdata, 1)
occurs = Vector{Int}(undef, n)
Threads.@threads for i in 1:n
occurs[i] = map(t-> t in searchset ? 1 : 0, textdata[i]) |> sum
end
occurs
end
function processS(textdata, searchset)
n = size(textdata, 1)
occurs = Vector{Int}(undef, n)
for i in 1:n
occurs[i] = map(t-> t in searchset ? 1 : 0, textdata[i]) |> sum
end
occurs
endCode language: Julia (julia)The result is just amazing! These are the results for the detection of all 200k words in all of 1 million phrases, on a Linux (x86_64-pc-linux-gnu) Intel(R) Xeon(R) CPU E5-2660 v3 @ 2.60GHz running 40 threads:
@time textdata, searchterms = fill(1_000_000);
1.287460 seconds (14.00 M allocations: 845.350 MiB, 58.86% gc time)
@time searchset = Set(searchterms[1:200_000]);
0.022542 seconds (10 allocations: 6.026 MiB)
@time result = processT(textdata, searchset); # 40 threads
0.033092 seconds (1.00 M allocations: 106.820 MiB)
@time result = processS(textdata, searchset); # single threaded
0.722141 seconds (1.00 M allocations: 106.801 MiB)Code language: Julia (julia)And these are the results on my Apple M1 Pro with 10 cores (8 performance and 2 efficiency) and 32 GB memory, running 8 threads:
@time textdata, searchterms = fill(1_000_000);
# 0.543755 seconds (14.22 M allocations: 858.079 MiB, 34.46% gc time, 5.28% compilation time)
@time searchset = Set(searchterms[1:200_000]);
# 0.010282 seconds (10 allocations: 6.026 MiB)
@time result = processT(textdata, searchset); # 8 threads
# 0.079716 seconds (1.12 M allocations: 113.163 MiB, 31.10% compilation time)
@time result = processS(textdata, searchset); # single threaded
# 0.439186 seconds (1.07 M allocations: 110.820 MiB, 3.45% compilation time)Code language: Julia (julia)")

