L’objectif de cet exercice est d’apprendre les rudiments de l’agrégation de données en géomatique. Nous agrégerons des données vectorielles ponctuelles dans des zones (polygones), puis nous apprendrons à générer une statistique zonale à partir de données raster.
Nous verrons aussi comment préparer les données raster pour rendre une statistique zonale possible.
Données de test et leur contexte
Populations
Fichier : populations.gpkg. Type: vectoriel, points.
Données de population de lieux-dits, issues d’Open Street Map. Ces données sont vectorielles, associées à une couche de points, et permettent une agrégation facile.
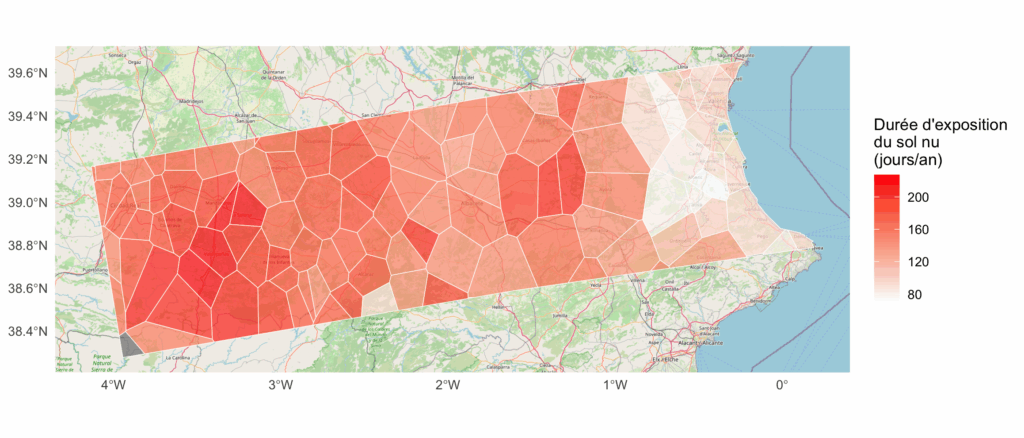
Durée d’exposition du sol nu
Fichiers: masked.tif (fichier nettoyé et optimisé, valeurs numériques agrégeables uniquement) et data_raw/*/*.tif (fichiers crus, incluant des codes spéciaux) Type: raster.
Pour illustrer l’agrégation de données raster, nous travaillerons avec l’exemple de l’indicateur agricole de durée d’exposition du sol nu après la récolte, en jours. Cette durée favorise l’érosion des sols agricoles (Gómez et Nearing, 2005). Le sol nu augmente le ruissellement et accroît les risques d’inondation et de sécheresse. Cette durée implique aussi une moindre densité spatiotemporelle de végétaux (quantité et nombre de jours de présence), autrement dit, une moindre séquestration du carbone, et l’augmentation des émissions de CO₂ via l’érosion et l’oxydation de la matière organique (qui agit normalement comme une éponge géante, améliorant la capacité de rétention d’eau du sol). La perte de couverture végétale après la récolte supprime en outre les habitats, déstabilise les microbiomes du sol et interrompt les cycles de régénération. En temps normal, les racines des cultures stabilisent le sol, créent des macropores (canaux) qui permettent à l’eau de s’infiltrer profondément dans le sol et absorbent l’eau. Lorsque la récolte est terminée et que la terre est laissée nue, cette infrastructure naturelle disparaît.
L’usage de cultures de couverture (seigle, trèfle, vesce plantés après la culture principale) permet de limiter ces problèmes.
La détection de la durée d’exposition du sol nu se fait par satellite. Une valeur n’existe pour un point donné de la surface terrestre que lorsque le satellite peut distinguer le sol de la végétation ou des surfaces bâties. Les forêts denses, les prairies permanentes, les glaciers, l’eau et les zones bâties n’exposent jamais suffisamment le sol pour que l’algorithme les classe comme « nus »: ces catégories d’usage du sol possèdent donc la valeur NA. Les régions agricoles génèrent la plupart des signaux détectables, car elles exposent régulièrement le sol (labour, intervalles entre les récoltes, périodes de jachère).
Les données proviennent de Copernicus Land Monitoring (CLMS), CLMS HRL – Bare Soil After (CPBSA) 2023, 10 m resolution.
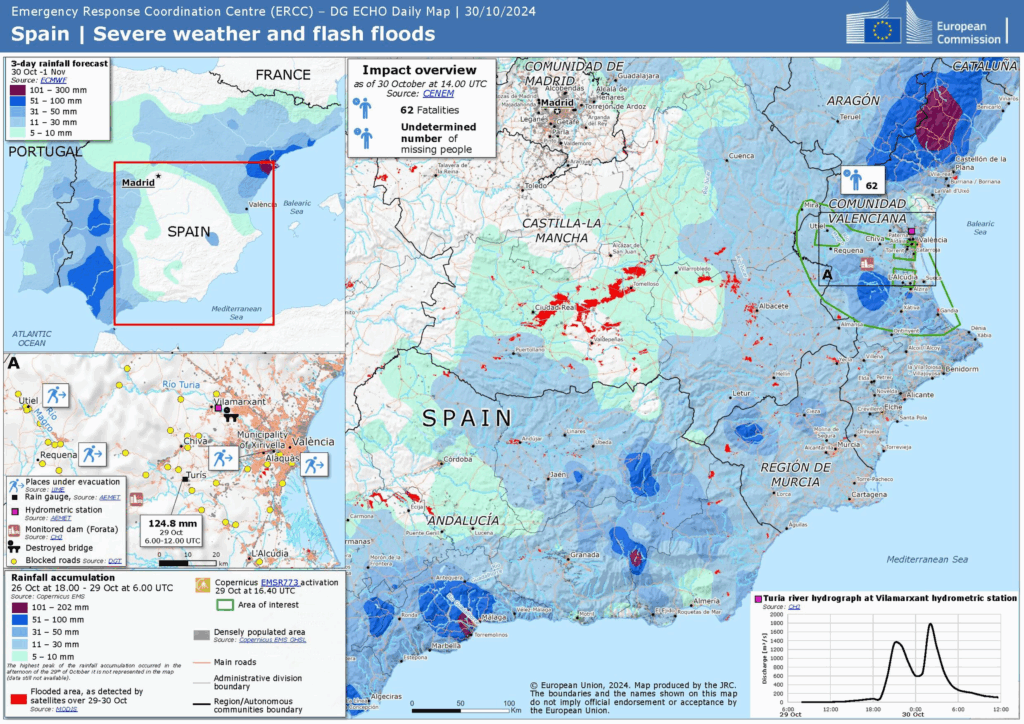
Le dataset, immense, couvre toute l’Europe. Nous allons nous centrer sur une région couvrant Valence et Castille la Manche, marquées par les pluies torrentielles et les inondations en 2024. Au-delà des aspects purement techniques, l’exercice nous permettra ainsi de méditer sur le rôle de l’agriculture intensive dans les « catastrophes naturelles », ou plutôt sur la dimension anthropogène des évènements climatiques extrêmes.
Zones
Fichier: zones.geojson, type: vectoriel, polygones.
Territoire couvrant l’étendue de masked.tif et subdivisé en zones par un diagramme de Voronoï que j’ai construit à partir de points localisant les prinicipalles localités de la région.
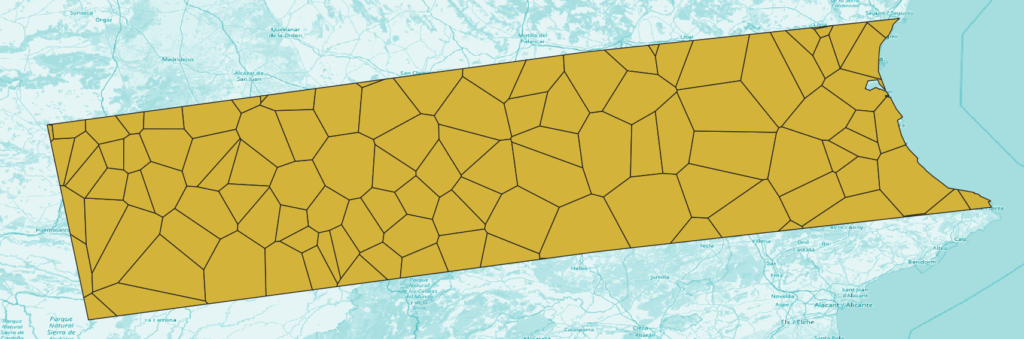
Avec QGIS
Ajoutez les données de l’exercice (que vous avez téléchargé et dézippé dans unine_exercice_agregation_geodonnees) à votre carte dans QGIS :
Agrégation de données ponctuelles dans les polygones contenants
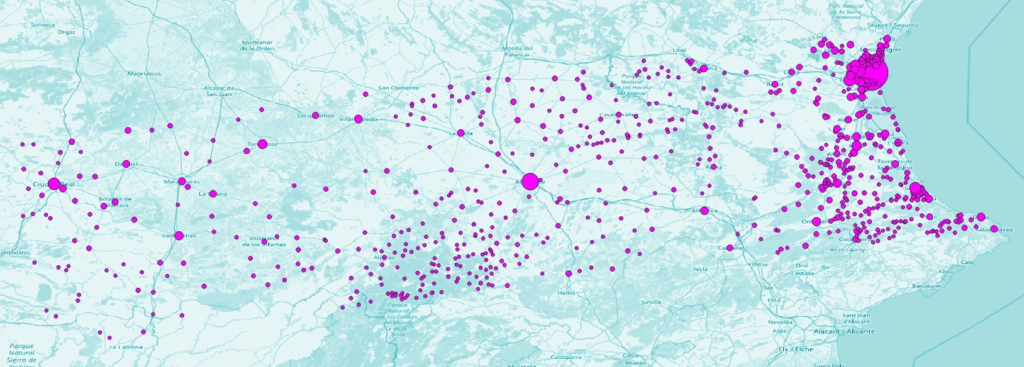
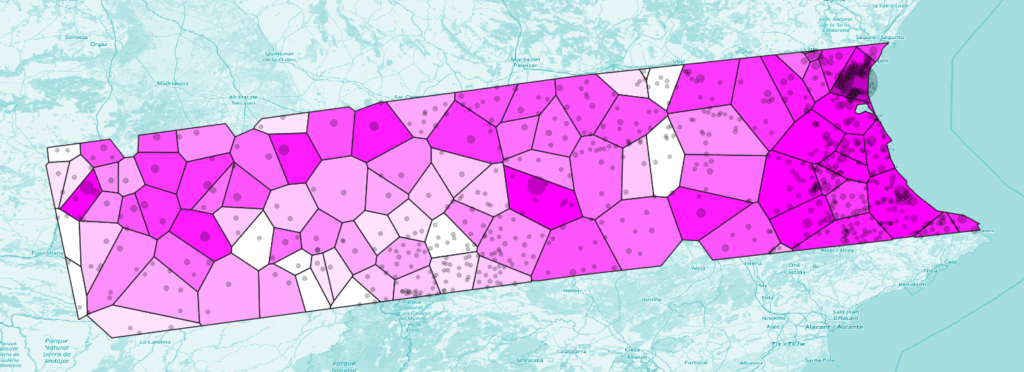
Nous allons ajouter les sommes des populations stockées dans les des points (places.gpkg) aux polygones zones.geojson.
Depuis Processing Toolbox, choisissez Vector general > Join attributes by location (summary).
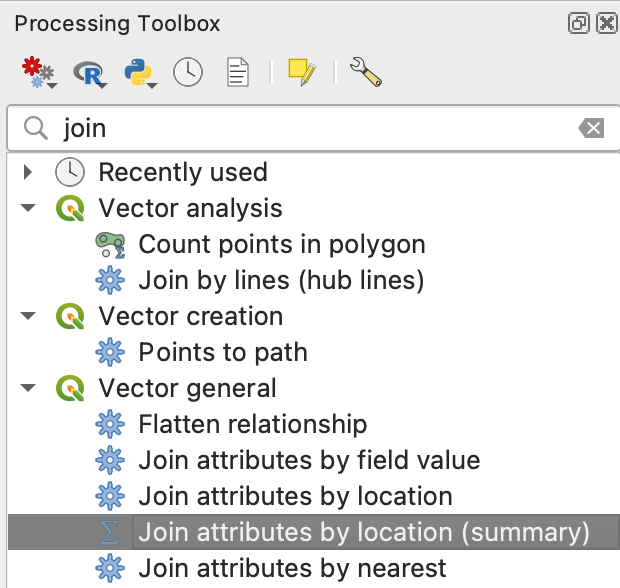
Dans la boîte de dialogue, spécifiez comme suit, en ajoutant « population » au champ « Fields to summarize » et « sum » au champ « Summaries to calculate« .
Il vous suffit dès lors d’attribuer un schéma de couleur à la couche polygonale produite pour obtenir une carte agrégée:
Agrégation de données raster dans les polygones contenants
Depuis Processing Toolbox, choisissez Raster analysis > Zonal statistics.
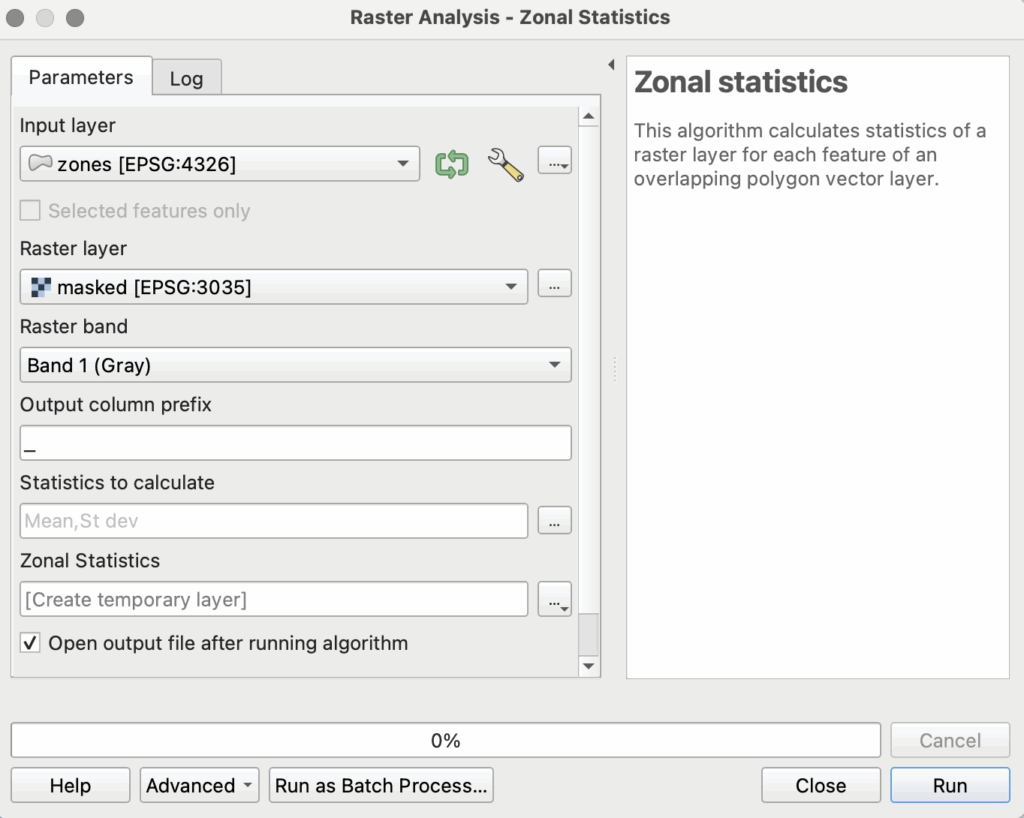
Dans « statistics to calculate« , ouvrez la liste à choix multiple […] et choisissez celles qui vous intéressent. Généralement, je recommande la moyenne (mean) et l’écart type (st-dev); ce dernier permet de vérifier si les données par zone ne sont pas trop hétérogènes, autrement dit si la moyenne veut vraiment dire quelque chose.
Notez que, si vous travailliez avec des données catégorielles (par exemple des catégories d’usage du sol) la statistique « majority » pourrait devenir utile. Elle vous permettrait d’attribuer le « type d’usage du sol le plus fréquent » à chaque zone (polygone). Ici, nous travaillons avec des valeurs numériques (nombre de jours) et pouvons calculer une moyenne plutôt qu’une majorité.
Il vous suffit dès lors d’attribuer un schéma de couleur à la couche polygonale produite pour obtenir une carte agrégée.

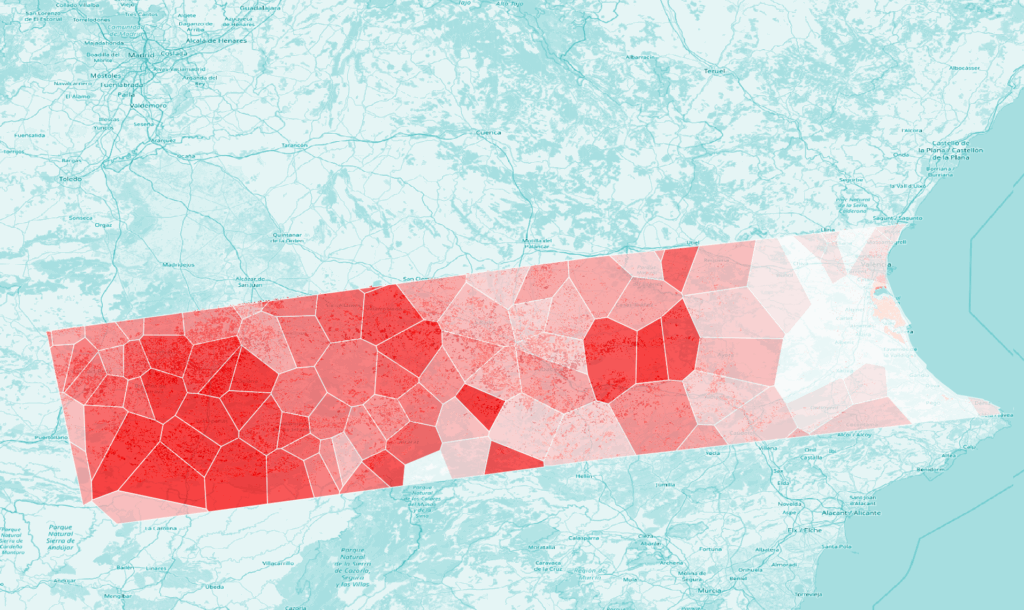
À méditer: quel lien voyez-vous entre ces résultats et la carte ERCC des inondations ci-dessous? Quels autres facteurs que les sols nus renforcent les effets des pluies torrentielles? Ces facteurs sont-ils identiques dans les zones urbaines et rurales? Vers quels types de zones se porte prioritairement l’attention médiatique en cas d’évènements climatiques extrêmes?
Préparation de données raster avec GDAL
Jusqu’ici, vous avez travaillé avec des géodonnées raster que je vous ai prémâchées pour vous encourager dans les premières étapes de l’exercice. Dans la vie réelle, les données viennent toujours sous forme d’un lot de fichiers qu’il faut d’abord comprendre, nettoyer et rassembler en un tout cohérent, avant toute tentative d’agrégation statistique.
À cette fin, QGIS représente plus un obstacle qu’un outil, parce que des paramètres essentiels sont inaccessibles par l’intermédiaire de son interface visuelle. Il devient donc pertinent de passer en ligne de commande (Terminal.app sur Mac OS) pour interagir directement avec GDAL. En réalité, QGIS est surtout une interface graphique construite par-dessus GDAL.
Si ce n’est pas encore fait, installez la nouvelle version de GDAL pour y accéder en ligne de commande.
Sur Mac OS, et en partant du principe que vous avez déjà installé Homebrew:
brew install gdalLangage du code : Shell Session (shell)Sur Windows, installez la suite complète OSGeo4W dont GDAL fait partie, ou utilisez l’installeur Conda:
conda install -c conda-forge gdalLangage du code : Shell Session (shell)Vérifiez les données
Tout d’abord, dirigez le terminal dans le dossier où vos fichiers raster crus sont déposés:
cd chemin/vers/unine_exercice_agregation_geodonnes/data_raw Vérifiez maintenant la structure des données d’origine à l’aide de la commande gdalinfo:
gdalinfo CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00.tifÉtudiez le rapport que vous venez de générer avec cette commande. Vous remarquez, entre autres que la projection de l’image est le ETRS89 (Système de référence défini par la sous-commission européenne EUREF de l’Association internationale de géodésie IAG en 1989), que la compression de l’image est de type LZW et que le type de données stockées dans chaque pixel est un entier court de type UInt16.
Savoir tout cela vous aidera beaucoup à manipuler les données de manière correcte par la suite.
Driver: GTiff/GeoTIFF
...
Coordinate System is:
PROJCRS["ETRS89-extended / LAEA Europe",
BASEGEOGCRS["ETRS89",...
...
Image Structure Metadata:
LAYOUT=COG
COMPRESSION=LZW
INTERLEAVE=BAND
...
Corner Coordinates:
Upper Left ( 3100000.000, 1900000.000) ( 4d 8' 2.55"W, 39d 9'54.04"N)
Lower Left ( 3100000.000, 1800000.000) ( 3d56'39.98"W, 38d16'32.14"N)
Upper Right ( 3200000.000, 1900000.000) ( 2d59'42.59"W, 39d19'32.86"N)
Lower Right ( 3200000.000, 1800000.000) ( 2d49'12.09"W, 38d26' 2.02"N)
Center ( 3150000.000, 1850000.000) ( 3d28'23.34"W, 38d48' 6.90"N)
Band 1 Block=512x512 Type=UInt16, ColorInterp=GrayLangage du code : Shell Session (shell)Vérifiez la stucture d’un autre fichier d’origine. Est-elle identique?
gdalinfo CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00.tif -histCombinez plusieurs fichiers raster
Nous avons 4 fichiers raster. Combinons-les en un seul pour nous faciliter la suite des tâches. Nous construisons d’abord un dataset virtuel merge.vrt:
gdalbuildvrt merge.vrt \
CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00.tif \
CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00.tif \
CLMS_HRLVLCC_CPBSA_S2023_R10m_E33N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E33N18_03035_V01_R00.tif \
CLMS_HRLVLCC_CPBSA_S2023_R10m_E34N18_03035_V01_R00/CLMS_HRLVLCC_CPBSA_S2023_R10m_E34N18_03035_V01_R00.tifPuis nous fabriquons un .tif unique à partir de ce dernier. Notez que je spécifie que la compression est LZW et que le type de données est Int16, comme nous l’avons appris plus haut à l’aide de gdalinfo. Autrement dit, je conserve la même compression et type que celle des fichiers d’origine; épargnant ainsi beaucoup de temps de traitement. Si vous oubliez de spécifier la compression, gdal_translate générera aussi un résultat, mais le fichier sera immense (vous passez d’une quarantaine de Mb à 4 Gb).
gdal_translate merge.vrt merged.tif \
-co COMPRESS=LZW \
-co PREDICTOR=2 \
-co TILED=YES \
-ot Int16
Enlevez les données non-numériques
Un fichier de géodonnées raster peut contenir des valeurs numériques qui sont en réalité des codes. Les prendre en compte dans une statistique numérique fausserait entièrement le résultat. Il faut donc les filtrer et ne conserver que des données effectivement numériques. Un coup d’œil au fichier .sld (Styled Layer Descriptor) généralement livré avec les données raster de type .tif ou autre permet de comprendre quelles données sont des codes. Pour notre set de données, nous trouvons:
CLMS_HRLVLCC_CPBSA_R10.sld
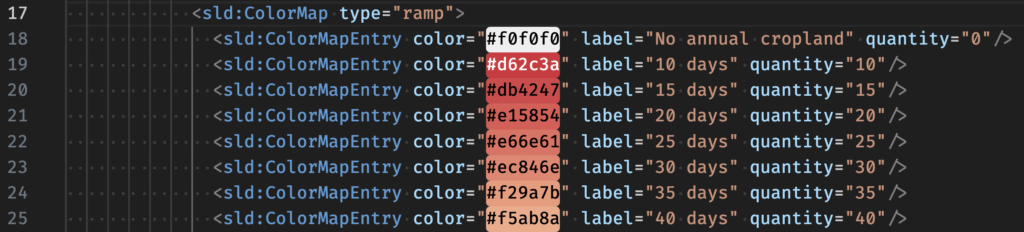
Comme on le voit le zéro (quantity = « 0 ») n’est pas à considérer comme un chiffre, vu qu’il signifie « No annual cropland« . Il en va de même pour les chiffres dépassant largement le nombre de jours maximal par année (65526, 65527…)

Filtrons donc toutes les valeurs >0 et <365 et stockons le résultat dans un nouveau fichier nommé masked.tif :
gdal_calc.py \
-A merged.tif \
--outfile=masked.tif \
--NoDataValue=-9999 \
--type=Int16 \
--calc="(A*(A>0)*(A<=365)) + (-9999)*( (A<=0)+(A>365) )" \
--co COMPRESS=LZW \
--co TILED=YES \
--co PREDICTOR=2Langage du code : JavaScript (javascript)La « ligne magique » de ce code est le calculateur de raster et la formule qu’on lui donne: (A*(A>0)*(A<=365)) + (-9999)*( (A<=0)+(A>365) )
La formule est appliquée à chaque cellule du raster. A est la valeur originale d’une cellule du raster. (A>0)retourne 1 si A est supérieur à zéro et 0 sinon. (A<=365) ne retourne 1 que si A est inférieur ou égal à 365. Réfléchissez au reste de cette formule et ne continuez qu’une fois que vous avez bien compris pourquoi cette formule retourne la valeur originale de la cellule (A) si elle est >0 et <365, et -9999 sinon.
La ligne --NoDataValue=-9999 veut dire que -9999 sera considéré comme valeur absente dans le calcul de la statistique zonale.
Le résultat du calcul est stocké dans le fichier masked.tif, autrement dit celui-même que je vous ai préfabriqué pour l’exercice. Il sera rare, dans vos professions, que quiconque vous préfabrique un fichier prêt à l’usage, il est donc important de manier les rudiments du nettoyage de données que nous venons de voir. Notez que, comme pour l’opération de combinaison de fichiers, je spécifie la compression (LZW) et le type (Int16), pour éviter de me retrouver avec un masked.tif de plusieurs Gigabytes.
L’approche tout en un avec R
Tout ce que nous venons de faire peut être reproduit de manière programmatique, plutôt que de passer par une interface graphique qui finira par vous faire perdre du temps. Par exemple dans R.
Chargez les bibliothèques dont vous avez besoin et définissez le chemin vers le dossier qui contiendra vos données d’exercice:
library(dplyr)
library(terra)
library(exactextractr) # fast extraction from Raster Datasets using Polygons
library(sf)
library(ggplot2)
mypath <- "/chemin/vers/votre/dossier"Langage du code : PHP (php)Téléchargez les données de l’exercice.
data_srdata_src_url <- "https://ourednik.info/unine/unine_exercice_agregation_geodonnees.zip"
download.file(
data_src_url,
file.path(mypath,"data.zip"),
mode = "wb"
)
unzip(file.path(mypath,"data.zip"), exdir=mypath)
exerdatapath <- file.path(mypath,"unine_exercice_agregation_geodonnees")Langage du code : R (r)Chargez les géométries des zones et les données ponctuelles. Notez que j’ajoute un numéro de id aux zones pour faciliter les agrégations par la suite
zones_file <- file.path(exerdatapath,"zones.geojson")
zones <- st_read(zones_file) %>% mutate(id = row_number())
places_file <- file.path(exerdatapath,"places.gpkg")
places <- st_read(places_file)
st_crs(zones) == st_crs(places) # vérification de l'équivalence des projections
# une visualisation pour vérifier
ggplot() +
geom_sf(data=zones, fill = "blue", color = "white") +
geom_sf(data = places, aes(size = population), color="hotpink", alpha=0.5)Langage du code : R (r)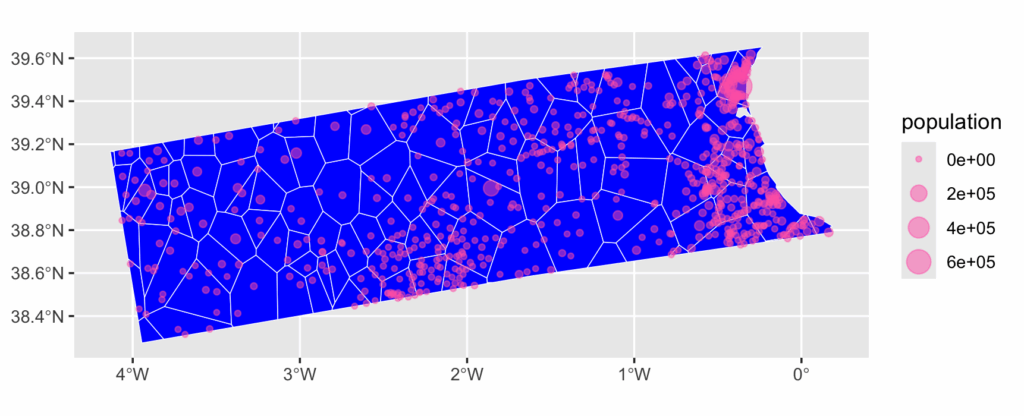
Produisez le fichier combiné et nettoyé masked.tif à partir des fichiers raster crus.
data_raw_src <- file.path(exerdatapath,"data_raw")
r1 <- rast(file.path(data_raw_src,"CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00","CLMS_HRLVLCC_CPBSA_S2023_R10m_E31N18_03035_V01_R00.tif"))
r2 <- rast(file.path(data_raw_src,"CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00","CLMS_HRLVLCC_CPBSA_S2023_R10m_E32N18_03035_V01_R00.tif"))
r3 <- rast(file.path(data_raw_src,"CLMS_HRLVLCC_CPBSA_S2023_R10m_E33N18_03035_V01_R00","CLMS_HRLVLCC_CPBSA_S2023_R10m_E33N18_03035_V01_R00.tif"))
r4 <- rast(file.path(data_raw_src,"CLMS_HRLVLCC_CPBSA_S2023_R10m_E34N18_03035_V01_R00","CLMS_HRLVLCC_CPBSA_S2023_R10m_E34N18_03035_V01_R00.tif"))
m <- mosaic(r1, r2, r3, r4)
masked <- ifel(m > 0 & m <= 365, m, -9999)
writeRaster(
masked,
"masked.tif",
overwrite = TRUE,
datatype = "INT2S", # Int16 signé
NAflag = -9999,
gdal = c("COMPRESS=LZW", "TILED=YES", "PREDICTOR=2")
)Langage du code : R (r)Agrégez les populations de places.gpkg dans zones.geojson
result <-
st_join(zones, places, join = st_contains) |> # spatial join points → polygons
group_by(id) |>
summarise(pop_sum = sum(population, na.rm = TRUE))Langage du code : HTML, XML (xml)Et visualisez le résultat
ggplot(result) +
geom_sf(aes(fill = pop_sum), color = "white") +
scale_fill_gradient(low = "white", high = "#ff00ff",
trans = "log10",
name = "Population (log)") +
labs(fill = "Population") +
geom_sf(aes(size = population), data = places, color = "black", stroke=0, alpha=0.2) +
theme_minimal()Langage du code : JavaScript (javascript)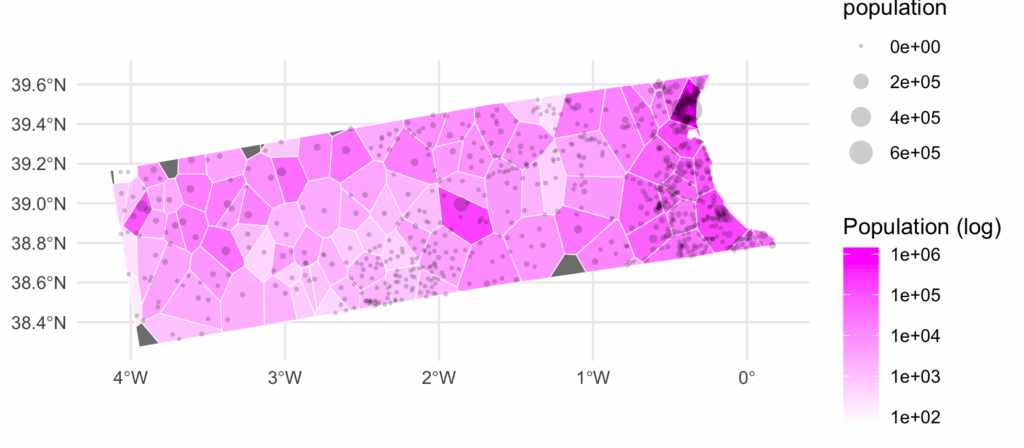
Et, enfin, la statistique zonale du raster par zone vectorielle:
library(raster)
r <- raster("masked.tif")
raster::NAvalue(r) <- -9999
stats <- exactextractr::exact_extract(
r, zones,
fun = c("mean", "stdev"),
progress = TRUE
)
zones$mean <- stats$mean
zones$sd <- stats$sdLangage du code : PHP (php)Et visualisez le résultat:
library(ggspatial)
ggplot() +
annotation_map_tile(type = "osm", zoom = 9) +
geom_sf(data=zones, aes(fill = mean), color = "white",
alpha = 0.7) +
scale_fill_gradient(low = "white", high = "#ff0000",
name = "Durée d'exposition\ndu sol nu\n(jours/an)") +
labs(fill = "Population") +
theme_minimal()Langage du code : JavaScript (javascript)