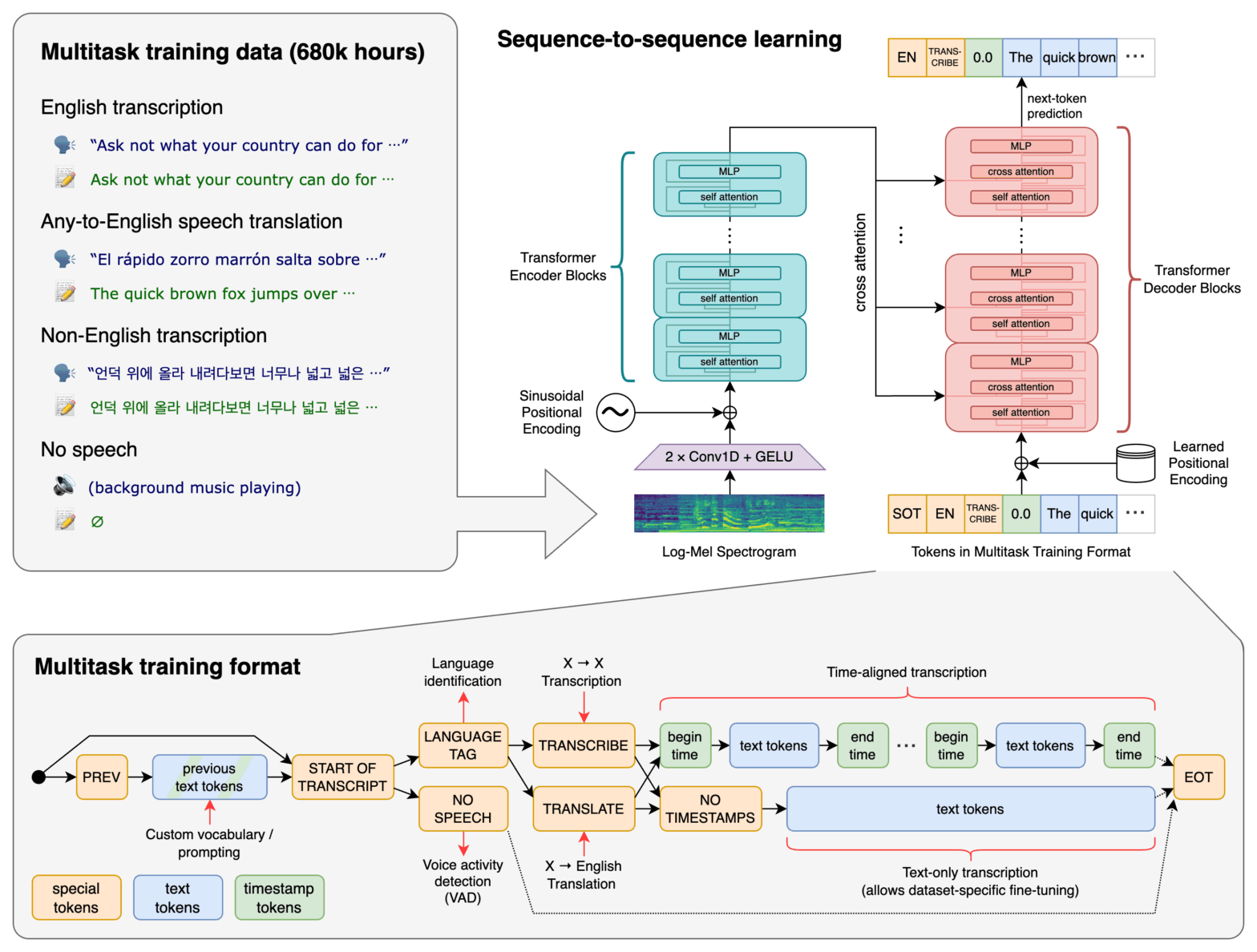
Une étude de terrain en sciences humaines génère souvent une grande quantité de fichiers audio qu’il faut transcrire dans votre travail de recherche. Une transcription vous permettra aussi d’exploiter vos textes à l’aide d’algorithmes de text mining.
Les tâches de transcription se laissent automatiser grâce l’intelligence artificielle et ce tutoriel propose quelques pistes.
Solutions open source
Type de solution fortement recommandée. Avec l’open source, vous savez à quoi vous avez affaire (la moindre ligne de code est vérifiable) et vous pouvez installer le modèle « en local » (sur votre propre ordinateur) en offrant donc plus de vie privée à vos interlocuteurs de terrain. Le seul désavantage est que cela exige un minimum de compétences informatiques.
OpenAI Whisper
L’appliciton Whisper est la plus reconnue dans le domaine de la transcription de fichiers audio. Son code est maintenu par OpenAI, entreprise aussi connue pour un certain chatbot…
Pour l’installer, rendez-vous sur:
https://github.com/openai/whisper
Vous pouvez directement suivre les instructions d’installation, mais je vous recommande d’installer Whisper dans un environnement virtuel Python. Cela vous permettra d’installer plus tard d’autres applications open source basées sur Python mais exigeant un autre environnement virtuel. Si les mots « Python » et « environnement virtuel » vous font peur, suivez simplement le présent tutoriel, ça va aller.
Miniconda
Téléchargez le gestionnaire de modules et d’environnements Python, Minicoda, et installez – le sur votre ordinateur:
https://www.anaconda.com/docs/getting-started/miniconda/install
Quand c’est fait, ouvrez l’interpréteur de commandes de votre système d’exploitation (Terminal.app sur Mac ou cmd.exe sur Windows) et exécutez le code suivant:
conda create -n nlp python=3.10 -yLangage du code : Bash (bash)Vous venez de créer un environnement nommé « nlp » (pour Natural Language Processing) avec un fond de Python en version 3.10.
ffmpeg
Installez FFmpeg, qui vous servira à traiter des fichiers son. Vous pouvez le faire avec une commande Conda ainsi
conda install -c conda-forge ffmpegLangage du code : Bash (bash)sachant que ffmpeg ne sera alors disponible que si conda est activé. Comme ce logiciel en ligne de commande est très utile pour les conversions de fichiers audio et vidéo, je vous recommande de l’installer séparément à l’aide de l’une des commandes suivantes, présupposant que vous avez installé Homebrew (Mac) ou Scoop (Windows). Si c’est trop dur, contentez-vous de l’installation de ffmpeg à l’aide de conda.
# sur Ubuntu or Debian avec APT
sudo apt update && sudo apt install ffmpeg
# sur MacOS avec Homebrew (https://brew.sh/)
brew install ffmpeg
# sur Windows avec Scoop (https://scoop.sh/)
scoop install ffmpegLangage du code : Bash (bash)Activer votre environnement « nlp »
conda activate nlp Langage du code : Shell Session (shell)PyTorch
PyTorch est une bibliothèque logicielle Python open source de machine learning développée par Meta. Vous en avez besoin pour Whisper. Installez PyTorch avec une commande correspondant à votre ordinateur à l’aide du générateur de commandes su https://pytorch.org/get-started/locally/ . Pour une machine Windows dotée d’une carte graphique supportant le protocole CUDA 11.8, par exemple, la configuration sera la suivante:
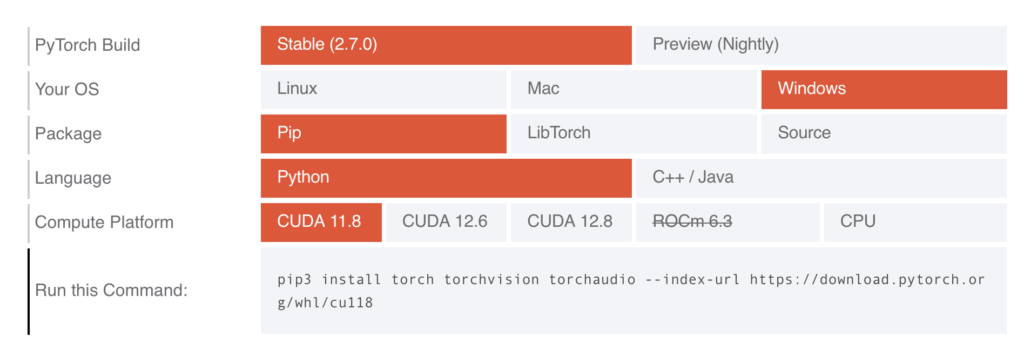
Et le code à utiliser est le suivant (sur Windows!)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Langage du code : JavaScript (javascript)Si vous avez un Mac, choisissez « Mac » dans « Your OS » et copiez la commande correspondante. L’option CUDA n’est disponible que sur une machine Windows ou Linux dotée d’une carte graphique Nvidia.
Sur un Mac, la version officielle de Pytorch préfère se contenter du CPU. Mais rien ne vous empêche d’installer une version de Pytorch capable d’exploiter les capacités IA des processeurs Apple Silicon Mx en suivant les instructions sur la page d’Apple. Je vous aide volontiers si vous avez le courage d’essayer.
Si vous ne connaissez pas votre version de CUDA, tapez nvcc --version dans votre interpréteur (Windows ou Linux). Si vous ne comprenez pas ce qu’est le CPU ou CUDA et que cela vous inquiète, appelez-moi à l’aide.
Rust
Il n’est pas toujours nécessaire d’installer un interpréteur du langage de programmation Rust, mais cela peut aider.
pip install setuptools-rustWhisper
Nous venons de passer la partie difficile de l’installation, avec les prérequis de Whisper. Installons maintenant l’application elle-même:
pip install git+https://github.com/openai/whisper.git Langage du code : JavaScript (javascript)Il reste à tester la conversion d’un fichier audio, sans oublier de spécifier la langue. Pour ce test, choisissez un petit fichier, pour éviter que votre invite de commandes ne soit bloquée en mode « j’affiche les résultats de Whisper ». Si cela vous arrive tout de même, vous pouvez interrompre l’exécution d’une ligne de commande en pressant la combinaison de touches « Ctrl+C »
whisper mon_fichier_audio.mp3 --language French --model smallLangage du code : Shell Session (shell)Whisper s’occupera de télécharger le modèle de langage nécessaire.
Pour sauvegarder le résultat dans un fichier, spécifier le format d’exportation et le dossier ou le fichier résultant sera stocké:
whisper mon_fichier_audio.mp3 --language French --model base --output_format txt --output_dir ./transcriptionsPour de meilleures performances au prix de plus de place sur votre dique dur, vous pouvez prendre d’autres modèles (medium, large, turbo) en les spécifiant dans le pramètre –model.
Pour traiter plusieurs fichiers
Si vous avez de nombreux fichiers à convertir, je vous recommande de tous les mettre dans un dossier et d’utiliser un bash-script. Ces scripts sont des instructions simples qu’il suffit d’exécuter, elles aussi, dans la ligne de commande. Imaginons que vous avez une série de fichiers de type mp3 dans le répertoire votre/dossier, et que vous souhaitez que whisper dépose les transcriptions dans le dossier /transcriptions, utilisez la commande suivante sur MacOS ou Linux:
for file in /votre/dossier/*.mp3; do
whisper "$file" --language French --model base --output_format txt --output_dir ./transcriptions
doneLangage du code : Bash (bash)Sur une machine Windows, la commande PowerShell sera comme suit:
$files = Get-ChildItem "C:\votre\dossier" -Filter *.mp3
foreach ($file in $files) {
whisper $file.FullName --language French --model base --output_format txt --output_dir .\transcriptions
}Langage du code : Bash (bash)Solutions commerciales
Avantages: Les solutions commerciales facilitent le workflow et ne demandent aucune compétence informatique.
Désavantages: Elles sont chères et exigent beaucoup de confiance de votre part. Elles sont souvent en ligne, sur le serveur du vendeur. Certaines emploient des personnes (sous-payées) réelles. À éviter si vos données sont sensibles.
| Outil | Fonctionnalités supplémentaires | Langages | Tarifs |
| Sonix | Résumés, topic modelling et sentiment analysis | 53+ | $10/h pay-as-you-go; $5/h avec abonnement |
| Trint | Résumés, traductions | 40+ | $80/mois min. Abonnement d’essai gratuit |
| HappyScribe | Soustitres | 120+ | $12/h |
| Amberscript | Soustitres | 70+ | $8/h min. |
| Verbit | Soustitres, résumés | 50+ | Starts at $29/h |
| TranscribeMe | IA ou transcriveu·r·se humaine | 10+ | $0,70/min humaine $0,07/min machine |
| 360Converter Offline transcriber | Hors ligne | Anglais, Français, Allemand, Espagnol, Chinois, Japonais, Russe, Italien | 99$ en une fois, pour un seul achat |